
Как связать две таблицы в запросе 1с
Обновлено: 04.05.2024
Доброго дня!
Проблема такая, делаю отчет, на скд, необходимо по бизнес процессу создать отчет. В отчете есть поле: ДатаПоступления.
Это вычисляемое поле. Вот так оно вычисляется: В БП есть поле ПлановыйСрок(тут указываются дни, 10,11 и тд) и есть дата задачи.
Эта ДатаПОступления = ДАтаЗадачи+ПлановыйСрок. Проблема в том что на определенно точке маршрута создается задача(тут и заполняется этот ПЛАНОВЫЙ СРОК). Я взял БП, Взял задачу по ней, связал их левым соединением(полным не вариант, потому что тогда выводится все задачи по БП, и получатеся тупо одна и таже строка выводится много раз), задал задаче параметр что точка маршрута = тойточкекотораямненужна. Все хорошо, все работает. Но проблема в том что отчет выводит только те процессы, в которых есть эта задача. Он не выводит те процессы в которых карта маршрута не дошла до этой точки маршрута. Всего БП 236. из них только в 88 есть задача(напомню из этой задачи мне нужна дата ее создания для того чтобы вычислить ДАТуПоступления). Сейчас у меня запрос выводит 88 записей. а надо чтобы он выводил все 236. и если где-то такоц задачи нет, то просто чтоб поле ДатаПоступления было пустым.
Прошу помощи)
Структура кода запроса в 1С легко изучить. Начнем от простого запроса к более сложным вариантам.
Выбрать
Любой запрос имеет команду ВЫБРАТЬ, после которой могут идти дополнительные параметры выборки, которые позднее рассмотрим отдельно:
ПЕРВЫЕ
РАЗЛИЧНЫЕ
РАЗРЕШЕННЫЕ
Далее идет список полей выборки.
Простейший запрос в 1С может иметь такой вид:
Данный запрос вернет таблицу, состоящую из одной строки и одной колонки, в которой будет числовое значение равное 1.
Усложняем запрос: добавим еще поля, разделив их запятой
ВЫБРАТЬ 1, 2, "3"
Этот запрос также вернет 1 строку, но уже с 3 колонками, две из которых содержат числа, а 3 строковое.
Система 1С автоматически присвоит этим полям имена «Поле1», «Поле2», «Поле3», что неплохо, но не всегда удобно, ведь полей может быть значительно больше.
Поэтому в языке запросов существует специальный оператор именования КАК , который идет после поля,
Предыдущий запрос можно представить в таком виде:
ВЫБРАТЬ 1 КАК Один, 2 КАК Два, "3" КАК ЦифраТриСтрокой
Имена полей задаются по правилам именования переменных: не могут начинаться со строки, содержать пробелы, не должны повторятся в одной выборке, а также отсутствовать (они поставятся автоматически).
Возможно опускать слово КАК, но лучше такой вариант не использовать, так как конструктор запросов это исправит:
ВЫБРАТЬ ссылка ссылка ИЗ Справочник.ФизическиеЛица
Такие простые запросы конечно имеют место в реальных условиях, как вспомогательные таблицы, но обычно требуется выборка из какого-то источника.
Для этого существует оператор ИЗ , в которой источник данных может быть реальной таблицей из базы данных, а также виртуальными таблицами, которые существуют к некоторым таким таблицами или же к временным таблицам.
Пример простого запроса к реальной таблице справочника:
ВЫБРАТЬ ссылка ИЗ Справочник.Контрагенты
В таких запросах мы можем указать конкретные поля, которые нам нужны или указать *.
ВЫБРАТЬ * ИЗ Справочник.Контрагенты
Такой вариант универсальный, но избыточное количество полей замедляет и усложняет их разбор позднее.
Вложенные таблицы
Также возможно обращение к вложенной таблице:
ВЫБРАТЬ * ИЗ Справочник.Контрагенты.КонтактнаяИнформация КАК КонтактнаяИнформация
Как видите, здесь мы впервые использовали именование таблицы, которое также упрощает работу при написании запроса, это дает возможность обращения по этому имени к полям:
ВЫБРАТЬ КИ.Ссылка ИЗ Справочник.Контрагенты.КонтактнаяИнформация КАК КИ //так иногда будет короче
Особенностью запросов к вложенным таблицам является то, что возможно обращение к родительской таблице через поле ссылка через точку.
ВЫБРАТЬ Ссылка.Наименование ИЗ Справочник.Контрагенты.КонтактнаяИнформация КАК КонтактнаяИнформация
Подобная возможность используется и при обращении к реквизитам ссылочных полей: система сама неявно соединит нужные таблицы, но использование такого обращения следует использовать реже (особенно при указании условий в виртуальных таблицах или условий соединения таблиц).
ВЫБРАТЬ Ссылка, ОсновнойДоговор.Наименование КАК НазваниеДоговора ИЗ Справочник.Контрагенты
В данном случае поле ОсновнойДоговор может быть пустым, тогда обращение к его наименованию не вызовет ошибку, но значение будет NULL, поэтому рекомендуется использовать ЕстьNULL.
Дополнительно
Вернемся к запросу
ВЫБРАТЬ КИ.Ссылка ИЗ Справочник.Контрагенты.КонтактнаяИнформация КАК КИ
В данном запросе, мы не выбираем поля из самой подтаблицы КонтактнаяИнформация, и в случае если в ней несколько строк, то в выборку попадут несколько строк с одинаковым содержимым.
Чтобы избежать этого можно воспользоваться служебным словом РАЗЛИЧНЫЕ: система устранит все дубли автоматически.
ВЫБРАТЬ РАЗЛИЧНЫЕ КИ.Ссылка ИЗ Справочник.Контрагенты.КонтактнаяИнформация КАК КИ
Если мы хотим ограничить результат выборки количеством записей (например сотней) используем ПЕРВЫЕ, но использовать ее необходимо с осторожностью (иногда эта команда срабатывает раньше, чем применяются условия запросов), следует тестировать запросы основательно.
ВЫБРАТЬ ПЕРВЫЕ 100 КИ.Ссылка ИЗ Справочник.Контрагенты.КонтактнаяИнформация КАК КИ
Последнее, что следует упомянуть при изучении основ выборки запросов 1С:
Команду «ПОМЕСТИТЬ », позволяющую помещать выборку в таблицу для многократного последующего использования.
Источник может также выборкой из запроса, указанной в скобках:
ВЫБРАТЬ * ИЗ (ВЫБРАТЬ * ИЗ Справочник.Контрагенты) КАК ВложеннаяТаблица
Использование вложенных запросов имеет смысл в случае, если в нем данные как-либо предварительно обрабатываются, а не как в вышеуказанном примере, где это излишне.
В целом, использование временных таблиц и вложенных запросов замедляет выборку, но парадокс в том, что их использование может дать нужный сигнал оптимизатору запросов и эффект получается положительный.
При больших исходных данных, следует проверять оба варианта использования, на предмет скорости исполнения, для принятия окончательного варианта запроса.
Регистр команд, имен и полей запроса не имеет значение: Выбрать и ВыБРатЬ равносильны.
Если бы рекламодатели тратили на улучшение своей продукции те деньги, которые они тратят на рекламу, их продукция не нуждалась бы в рекламе.
— Уилл Роджерс
В отличии от соединения таблиц, объединение производит присоединение данных к таблице с абсолютно одинаковым количеством колонок.
Возможно 2 варианта объединения:
При этом не производятся никакие проверки — это простая операция:
- Значения полей могут быть различного типа.
- Если количество полей различно, система выдаст ошибку — «Разное количество полей объединяемых в запросах».
- Первая таблица считается главной — именно из нее берутся имена полей результирующей выборки (конструктор удаляет псевдонимы, если они присутствуют, автоматически).
- Нет явного ограничения количества таких объединений.
Внешний вид объединения в конструкторе запросов:
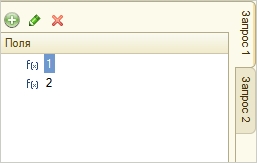
Добавляются эти запросы на вкладке «Объединение/Псевдонимы»

Здесь же можно управлять режимом объединения (флажки «Без дублей»):

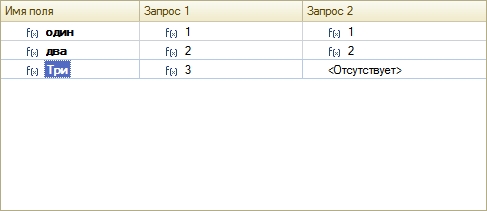
При добавлении поля в одну из таких таблиц (в режиме конструктора), в остальные таблицы добавляется значение NULL — автоматического подбора по именам источника не происходит. В этом случае приходится подредактировать текст запроса руками.
Если в объединении присутствуют неопределенное или пустые поля, такая процедура может происходить не полностью (режим ОБЪЕДИНИТЬ) — не все строки включаются в результат. Такое было замечено однократно, возможно, было связано с какой-то версией платформы, либо с использованием агрегирующих функции запроса.
Объединение больших выборок может влиять на производительность запроса: так как ведётся поиск дублей строк.
Только не говорите, пожалуйста, моей матери, что я работаю в рекламном агентстве. Она думает, что я служу тапером в борделе.
— Жак Сегела
В данной статья я расскажу о решении задачи, цель которой в проверке набора записей на сложные (комбинированные) условия вида "в иерархии", с акцентом на производительность решения (т.е. запросы в цикле не используем). Первая часть статьи - это постановка проблемы, вторая - это решение задачи с использованием метода Nested Sets. Если вам не интересны прелюдии, смело переходите ко второй части, там вся суть.
Часть 1. Формулирование проблемы.
Представьте себе задачу: необходимо проверить некоторый набор данных на условие иерархического вхождения его элементов (этого набора) в элементы более высокого уровня (например, группы), вот только групп может быть несколько и выбор той или иной группы также имеет определённые условия.
Чтобы было легче, вот более реальный пример (хотя пример все же выдуман, но для раскрытия темы будет вполне достаточно):
Есть справочник "Номенклатура". Справочник имеет иерархию Групп и элементов, уровень вложенности неограничен (на самом деле не важно, что это будет за иерархия: элементов или групп). Также, для произвольной группировки номенклатуры, имеется справочник "Сегменты номенклатуры". У справочника с сегментами есть табличная часть, где указывается какая номенклатура входит в данный сегмент, причем могут указываться как конкретные позиции номенклатуры, так и группы номенклатуры. Каждому сотруднику предприятия может быть указан один сегмент. Тем самым определяется доступная номенклатура, которую может заказать этот сотрудник. Сотрудники регулярно что-то заказывают, но делают это внесистемно – пишут служебки и относят их ответственному пользователю, который вводит один общий документ, где указывает сотрудников и то, что они заказывают. Документ имеет табличную часть с колонками «Сотрудник», «Номенклатура», «Количество». При проведении документа требуется реализовать проверку, которая убедится, что все заказали только то, что им разрешено.
Если не вдаваться в детали, то на первый взгляд решение задачи проблем не вызывает: взять таблицу из документа, для каждого пользователя определить сегмент и выяснить входит ли заказанная номенклатура в сегмент. Но есть нюанс. Так как в сегментах может быть определена группа, то это означает, что в запросе мы получим соединение таблиц, где проверка условия будет строится по выражению «В иерархии». Вот запрос, который бы решил задачу:
ВЫБРАТЬ
ВТ_Заказы.Сотрудник КАК Сотрудник,
ВТ_Заказы.Сегмент КАК Сегмент,
ВТ_Заказы.Номенклатура КАК Номенклатура,
СегментыСостав.Номенклатура КАК НоменклатураСегмента
ИЗ
ВТ_Заказы КАК ВТ_Заказы
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Сегменты.Состав КАК СегментыСостав
ПО ВТ_Заказы.Сегмент = СегментыСостав.Ссылка
И (ВЫБОР
КОГДА СегментыСостав.Номенклатура.ЭтоГруппа
ТОГДА ВТ_Заказы.Номенклатура В ИЕРАРХИИ (СегментыСостав.Номенклатура)
ИНАЧЕ ВТ_Заказы.Номенклатура = СегментыСостав.Номенклатура
КОНЕЦ)
ГДЕ
СегментыСостав.Ссылка ЕСТЬ NULL
Но 1С так делать не умеет. Выражение в скобках после оператора «В ИЕРАРХИИ» (подчеркнуто и выделено жирным) может быть либо параметром, либо вложенным подзапросом. В обоих случаях нас это не устраивает. Так как еще есть условие на равенство сегмента, соответственно в выборке может быть много сегментов с различными группами.
Можно рассмотреть решение с запросом в цикле: первый запрос вернет требуемые сегменты, затем в цикле для каждого из них получить содержимое и сделать проверку на данных из документа. Но ведь каждый знает, что запрос в цикле — это моветон, кошмар для производительности.
Другой вариант, это реализовать регистр, который будет хранить пономенклатурный состав сегмента. В целом это спасает. Вопрос только как его поддерживать в актуальном состоянии: понятное дело обновлять при записи сегмента, но также нужно следить еще и за изменением структуры в самом справочнике с номенклатурой. Этот вариант тоже отложим в сторону.
Еще есть вариант использовать механизмы СКД (как это делается для сегментов ERP/УТ), но это не чистые запросы 1С и по сути получим тот же неявный запрос в цикле.
Наш вариант другой – научить 1С работать с Nested Sets деревьями!
Часть 2. Nested Sets в 1С.
Немного теории.
Хранить иерархические структуры в базах данных можно по-разному. 1С для этого использует вариант, когда для каждого элемента указывается его родитель. Данный метод называется "Adjacency List" (переводится как "Список смежных вершин"). Такой метод конечно имеет право на жизнь и для большинства задач он вполне достаточен, но, что касается выполнения условий на вхождения в группы, то здесь он просто ужасен (что видно из описанного выше примера).
Для задач на проверку вхождения в иерархию гораздо лучше подходит метод Nested Sets (можно перевести как "Вложенные множества"). Данный метод подразумевает, что каждый элемент хранит в себе диапазон вложенных в него элементов. Это достигается путем использования пары ключей: lgt - left key и rgt - right key (см. картинку к статье). Соотвенно, left key (левый ключ) определяет начало диапазона, а right key (правый ключ) - его конец. Откуда же берутся ключи? Для того, чтобы получить ключи нужно обойти все дерево против часовой стрелки (слева направо) начиная с его корневого элемента. Это что-то вроде задачек для детей - нарисуй домик не отрывая карандаша, только вместо домика - граф (наше дерево). Так вот, ставим карандаш в корень (получаем первый левый ключ), далее спускаемся до ближаешего крайнего левого узла (получаем левый ключ номер два), далее еще ниже до тех пор пока не дойдем до самого крайнего элемента данной (крайней левой) ветки. От этого элемента начинаем подниматься назад вверх, при этом заполняются уже правые ключи. Поднимаемся до первой развилки и опять спускаемся вниз по тем элементам где еще не были. И так далее пока не будет обрисован весь граф (всё дерево).
В результате все ключи получаются уникальными, правый всегда больше левого, а диапазон ключей на любой элементе включает в себе диапазоны ключей всех вложенных внего узлов (см. картинку к статье).
Практика.
Для реализации структуры данных, которая будет хранить дерево в формате Nested Sets подойдет регистр сведений. Если продолжить рассматривать пример из первой части статьи то, для номенклатуры можно реализовать периодический (в пределах секунды) регистр сведений "Номенклатура Nested Sets": измерение "Номенклатура" (тип спр. "Номенклатура"); ресурсы: Левый ключ (Число(10,0)), Правый ключ (Число(10,0)), Уровень(Число(10,0)).
Итоговая конфигурация (выгрузка) приложена к статье.
При добавлении новых позиции номенклатуры и удаления существующих происходит пересчет ключей в Nested Sets. Для этого в обработчики событий "При записи" и "Перед удалением" добалены вызовы соответствующих процедур: "ДобавитьУзелВМножество(Номенклатура, Отказ)" и "УдалитьУзелИзМножества(Номенклатура, Отказ)". Сами процедуры вынесены в модуль менеджера рег. сведений "Номенклатура Nested Sets".
Все действия с пересчетом ключей можно разделить на 3 вида:
- Добавление нового узла (реализовано в процедуре "ДобавитьУзелВМножество", если условия на проверку существования узла = Ложь);
- Перемещение узла (изменение родителя) (реализовано в процедуре "ДобавитьУзелВМножество", если условия на проверку существования узла = Истина);
- Удаление узла (реализовано в процедуре "УдалитьУзелИзМножества")
1. При добавлении нового узла определяется родитель. Если его нет (узел добавляется в корень), то берется максимальное значение правого ключа (по всему дереву) и добавляется "1" - таким образом получается значение левого ключа нового узла. При этом остальные узлы не пересчитываются. Если родитель определен, то берется правый ключ родителя и он становится значением левого ключа нового узла. После этого происходит пересчет ключей всех узлов, стоящих "справа" от нового (что логично, все ключи сдвигаются на 2, узлы "слева" не задействуются). Правый ключ нового узла определяется как Левый ключ + 1 (ведь мы добавили всего один узел без вложенной ветки).
2. Перемещение узла самая сложная часть алгоритма. Следует разделить перемещение на 2 типа: вверх по дереву (с увеличением ключа новой позиции) и вниз по дереву (когда ключ позиции уменьшается). Перемещение всегда происходит без добавления и удаления узлов. Существующий узел перемещается на новую позицию. Старая и новая позиции узла определяют левую и правую границы. Левая граница - ветка, на которую переместился узел при направлении перемещения "влево", либо ветка, с которой переместился узел при направлении перемещения "вправо". Правая граница - соответственно, ветка, на которую переместился узел при направлении перемещения "вправо", либо ветка, с которой переместился узел при направлении перемещения "влево". Независимо от направления при перемещении всё множество узлов можно разделить на 5 групп:
- Узлы, ключи которых не изменяются. Ведь если мы перемещаем ветку в пределах двух позиций, то все, что находится за этими позициями, не изменяется. Новые элементы не добавляются, старые не удаляются, количество элементов постоянно, вот и ключи элементов до начала левой границы смещения и после правой границы остаются прежними;
- Узлы, у которых изменяются 2 ключа сразу. Это узлы между левой и правой границей. При перемещении влево их индексы увеличиваются на дельту. Где дельта - это разница между правым и левым ключом перемещаемого узла плюс единица (длина ветки исходящей от узла). При перемещении вправо индексы уменьшаются на эту дельту;
- Узлы, у которых изменяется правый ключ. Это узлы, которые проходят по левой границе смещения. Изменение происходит на величину дельты;
- Узлы, у которых изменяется левый ключ. Это узлы, которые проходят по правой границе смещения. Изменение происходит на величину дельты;
- Узлы, входящие в перемещаемую ветку. Их может и не быть если перемещается один только узел без вложенных элементов. Все такие узлы изменяются на величину смещения. Где смещение - это разница между старым левым ключом и новым левым ключем (длина переноса узла). Старый левый ключ - левый ключ старого положения узла, новый левый ключ - ключ нового положения. Следует учесть, что при перемещении вправо к смещеию добавляется величина дельты. В коде также используется понятие "БлижайшийПравыйКлюч" - под ним следует понимать правый ключ ближайшего элемента. Левый ключ нового узла равен "БлижайшийПравыйКлюч" + 1.
Стоит отметить, что в реализованном мною алгоритме не учитывается позиции, в которую перемещается узел в пределах родителя - узел всегда помещается как последний в пределах подчинения родителю. Для решения задач на вложенность элементов этого вполне достаточно.
Ниже приведен листинг процедуры "ДобавитьУзелВМножество":
3. Удаление узла не сильно отличается от его добавления. Стоит лишь учесть, что при удалении узла удаляется вся ветка (все вложенные узлы). В системе такого не должно быть при нормальных условиях. Но если кто-то удалит группу не удостоверившись, что на нее ссылаются вложенные элементы, то тут как раз и отработает наш алгоритм сполна.
Ниже приведен листинг процедуры "ДобавитьУзелВМножество":
В моей реализации я сделал регистр сведений "НоменклатураNestedSets" периодическим с целью увеличения производительности. Объясню: в примерах по использованию Nested Sets в интернетах используется команда UPDATE SQL сервера, такого 1С не может. Либо записывай набор записей целиком на весь регистр, либо пиши по одной записи. Если рассматривать спр. Номенклатура, то он спокойно может перевалить за 100 000, и каждый раз писать весь набор (с предшествующим удалением) это будет накладно. Писать по одной записи, тоже плохо (обращение к СУБД в цикле). Остается вариант использование периодического регистра: записывать только измененные позиции на текущую секунду, везде в запросах брать срез последних по регистру, а регламентным заданием чистить регистр. Собственно, такой вариант я и выбрал. Конечно он не идеален (2 записи в одну секунду не осилит), но для того чтобы показать алгоритм работы с Nested Sets подойдет.
Ну и на конец сам проверка на вхождение в иерархию, сделал ее в обработке проведения документа. Листинг ниже:
Соединение таблиц в запросе 1с может быть нескольких видов: ВНУТРЕННЕЕ, ЛЕВОЕ ,ПРАВОЕ, ПОЛНОЕ СОЕДИНЕНИЕ за котором указывается ПО.
Виды соединений таблиц


Таким образом, при описании связи таблиц к тексту запроса конструктор добавляет
ключевые слова ВНУТРЕННЕЕ / ЛЕВОЕ / ПРАВОЕ / ПОЛНОЕ СОЕДИНЕНИЕ… ПО.
В случае, если в запросе участвуют несколько таблиц, в окне конструктора запроса
становится доступной закладка Связи, на которой задается тип связи и условие связи
между таблицами. В тех случаях, когда это возможно, платформа сама устанавливает
связь между источниками запроса по ссылочным полям.
Рассмотрим различные виды связей на примере 2-х регистров:
- Регистра сведений Цены;
- Регистра накопления Остатки Номенклатуры.
Регистр сведений Цены имеет следующие Измерения и Ресурсы:

Регистр накопления ОстаткиНоменклатуры имеет следующие Измерения и Ресурсы:

Заполним регистры следующим образом:
Регистр накопления ОстакиНоменклатуры содержит данные.

Регистр сведений Цены выглядит так.

Безусловное(декартово произведение)
Таблицы и поля в конструкторе запросов настроим как на рисунке ниже. Связи отсутствуют.

Результат выполнения запроса сохраним в отчет. Подробно о создании отчетов можно посмотреть в бесплатном уроке Отчеты в 1с : Предприятии. Ссылка для скачивания отчета файл.

Внутреннее соединение таблиц в запросе 1с
Таблицы и поля полностью соответствуют предыдущему заданию. Добавиться связи на вкладке связи

Результат выполнения запроса сохраним в отчет. Ссылка для скачивания отчета файл.

Левое соединение таблиц в запросе 1с
Таблицы и поля полностью соответствуют предыдущему и первому заданию. Изменим связи на вкладке связи

Результат выполнения запроса сохраним в отчет. Ссылка для скачивания отчета файл.

Правое соединение таблиц в запросе
Таблицы и поля в данном случае полностью соответствуют предыдущему и первому заданию. Изменим связи на вкладке связи

Замечание: При установки галочки в конструкторе запроса соединение остается левым но меняется порядок полей. Также можно вручную заменить слово ЛЕВОЕ на ПРАВОЕ в тексте запроса.
Результат выполнения запроса сохраним в отчет. Ссылка для скачивания отчета файл.

Полное соединение таблиц в запросе 1с
Таблицы и поля в данном случае полностью соответствуют предыдущему и первому заданию. Изменим связи на вкладке связи

Код запроса измениться вместо ПРАВОЕ соединение будет ПОЛНОЕ.

Соединение таблиц в запросе используется при работе с двумя и более таблицами. Имеется 5 видов соединений. Нами рассмотрен пример использования всех возможных видов соединений.
Читайте также: