
Как связать таблицы в mysql workbench
Обновлено: 25.04.2024
Double-clicking a relationship on the EER diagram canvas opens the relationship editor. This has two tabs: Relationship , and Foreign Key .
Relationship Tab
In the Relationship tab, you can set the caption of a relationship using the Caption field. This name displays on the canvas and is also the name used for the constraint itself. The default value for this name is fk_ source_table_destination_table . Use the Model menu, Menu Options menu item to set a project-specific default name for foreign keys. To change the global default, see Section 3.2.4, “Modeling Preferences”.
You can also add a secondary caption and a caption to a relationship.
The Visibility Settings section is used to determine how the relationship is displayed on the EER Diagram canvas. Fully Visible is the default but you can also choose to hide relationship lines or to use split lines. The split line style is shown in the following figure.
Figure 9.17 The Split Connector

A broken line connector indicates a non-identifying relationship. The split line style can be used with either an identifying relationship or a non-identifying relationship. It is used for display purposes only and does not indicate anything about the nature of a relationship.
To set the notation of a relationship use the Model menu, Relationship Notation menu item. For more information, see Section 9.1.1.1.5.4, “The Relationship Notation Submenu”.
Foreign Key Tab
The Foreign Key tab contains several sections: Referencing Table , Cardinality and Referenced Table .
The Mandatory check boxes are used to select whether the referencing table and the referenced table are mandatory. By default, both of these constraints are true (indicated by the check boxes being checked).
The Cardinality section has a set of radio buttons that enable you to choose whether the relationship is one-to-one or one-to-many. There is also a check box that enables you to specify whether the relationship is an identifying relationship.
Перевод цикла из 15 статей о проектировании баз данных.
Информация предназначена для новичков.
Помогло мне. Возможно, что поможет еще кому-то восполнить пробелы.
Руководство по проектированию баз данных.
1. Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о проекте вашей базы данных. Хороший проект базы данных, как было сказано ранее, обеспечит целостность данных и простоту их обслуживания.
Структурированный язык запросов (SQL).
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван Структурированный язык запросов или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка. Ниже приведен пример запроса на выборку данных и его результат.
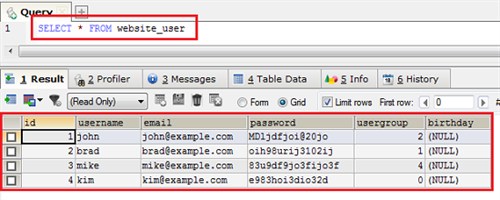
SQL – большая тема для повествования и его рассмотрение выходит за рамки данного руководства. Данная статья строго сфокусирована на изложении процесса проектирования баз данных. Позднее, в отдельном руководстве, я расскажу об основах SQL.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.

Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь», как на рисунке (Пример взят из MySQL Workbench).
Примеры.
В качестве примеров в руководстве я использовал ряд приложений.
РСУБД, которую я использовал для создания таблиц примеров – MySQL. MySQL – наиболее популярная РСУБД и она бесплатна.
Утилита для администрирования БД.
После установки MySQL вы получаете только интерфейс командной строки для взаимодействия с MySQL. Лично я предпочитаю графический интерфейс для управления моими базами данных. Я часто использую SQLyog. Это бесплатная утилита с графическим интерфейсом. Изображения таблиц в данном руководстве взяты оттуда.
Визуальное моделирование.
Существует отличное бесплатное приложение MySQL Workbench. Оно позволяет спроектировать вашу базу данных графически. Изображения диаграмм в руководстве сделаны в этой программе.
Проектирование независимо от РСУБД.
Важно знать, что хотя в данном руководстве и приведены примеры для MySQL, проектирование баз данных независимо от РСУБД. Это значит, что информация применима к реляционным базам данных в общем, не только к MySQL. Вы можете применить знания из этого руководства к любым реляционным базам данных, подобным Mysql, Postgresql, Microsoft Access, Microsoft Sql or Oracle.
В следующей части я коротко расскажу об эволюции баз данных. Вы узнаете откуда взялись базы данных и реляционная модель данных.
2. История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.

Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.
Выше приведен пример того, как такой файл мог бы выглядеть. Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок 'Database Design Tutorial', то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова 'Database Design Tutorial' и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или “запись” содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок (title) и его категория (category).
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию. Это намного быстрее, чем поиск по файлу строка за строкой, подобно тому, как это делает программа в текстовом файле.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
— Oracle – используется преимущественно для профессиональных, больших приложений.
— Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
— Mysql – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
— IBM – имеет ряд РСУБД, наиболее известна DB2.
— Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
В следующей части я расскажу кое-что о характеристиках реляционных баз данных.
3. Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом. Зачастую, первичный ключ это автоматически увеличиваемое (автоинкрементное) число (1,2,3,4 и т.д). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки (записи) другой таблицы, тем самым, связывая эти записи вместе.
Используя структурированный язык запросов (SQL), данные из разных таблиц, которые связаны ключом, могут быть выбраны за один раз. Для примера вы можете создать запрос, который выберет все заказы из таблицы заказов (orders), которые принадлежат пользователю с идентификатором (id) 3 (Mike) из таблицы пользователей (users). О ключах мы поговорим далее, в следующих частях.

Столбец id в данной таблице является первичным ключом. Каждая запись имеет уникальный первичный ключ, часто число. Столбец usergroup (группы пользователей) является внешним ключом. Судя по ее названию, она видимо ссылается на таблицу, которая содержит группы пользователей.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.

Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
— ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
— ввод индекса региона с длинной этого самого индекса в сотню символов
— создание пользователей с одним и тем же именем
— создание пользователей с одним и тем же адресом электронной почты
— ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN. Как и упоминалось ранее, SQL в данном руководстве обсуждаться не будет. Я сосредоточусь на проектировании баз данных.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.

Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Как говорилось ранее, проектирование базы данных – это вопрос идентификации данных, их связи и помещение результатов решения данного вопроса на бумагу (или в компьютерную программу). Проектирование базы данных независимо от РСУБД, которую вы собираетесь использовать для ее создания.
Связи — это довольна важная тема, которую следует понимать при проектировании баз данных. По своему личному опыту скажу, что осознав связи, мне намного легче далось понимание нормализации базы данных.
1.1. Для кого эта статья?
Эта статья будет полезна тем, кто хочет разобраться со связями между таблицами базы данных. В ней я постарался рассказать на понятном языке, что это такое. Для лучшего понимания темы, я чередую теоретический материал с практическими примерами, представленными в виде диаграммы и запроса, создающего нужные нам таблицы. Я использую СУБД Microsoft SQL Server и запросы пишу на T-SQL. Написанный мною код должен работать и на других СУБД, поскольку запросы являются универсальными и не используют специфических конструкций языка T-SQL.
1.2. Как вы можете применить эти знания?
- Процесс создания баз данных станет для вас легче и понятнее.
- Понимание связей между таблицами поможет вам легче освоить нормализацию, что является очень важным при проектировании базы данных.
- Разобраться с чужой базой данных будет значительно проще.
- На собеседовании это будет очень хорошим плюсом.
2. Благодарности
Учтены были советы и критика авторов jobgemws, unfilled, firnind, Hamaruba.
Спасибо!
3.1. Как организовываются связи?
Связи создаются с помощью внешних ключей (foreign key).
Внешний ключ — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
3.2. Виды связей
Связи делятся на:
- Многие ко многим.
- Один ко многим.
- с обязательной связью;
- с необязательной связью;
- Один к одному.
- с обязательной связью;
- с необязательной связью;
4. Многие ко многим
Представим, что нам нужно написать БД, которая будет хранить работником IT-компании. При этом существует некий стандартный набор должностей. При этом:
- Работник может иметь одну и более должностей. Например, некий работник может быть и админом, и программистом.
- Должность может «владеть» одним и более работников. Например, админами является определенный набор работников. Другими словами, к админам относятся некие работники.
4.1. Как построить такие таблицы?
Мы уже имеем две таблицы, описывающие работника и профессию. Теперь нам нужно установить между ними связь многие ко многим. Для реализации такой связи нам нужен некий посредник между таблицами «Employee» и «Position». В нашем случае это будет некая таблица «EmployeesPositions» (работники и должности). Эта таблица-посредник связывает между собой работника и должность следующим образом:
Слева указаны работники (их id), справа — должности (их id). Работники и должности на этой таблице указываются с помощью id’шников.
На эту таблицу можно посмотреть с двух сторон:
- Таким образом, мы говорим, что работник с id 1 находится на должность с id 1. При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
- Мы также можем сказать, что должности с id 3 принадлежат пользователи с id 2 и 3. Т.е., каждой роли справа принадлежит некий работник слева.
4.2. Реализация

С помощью ограничения foreign key мы можем ссылаться на primary key или unique другой таблицы. В этом примере мы
- ссылаемся атрибутом PositionId таблицы EmployeesPositions на атрибут PositionId таблицы Position;
- атрибутом EmployeeId таблицы EmployeesPositions — на атрибут EmployeeId таблицы Employee;
4.3. Вывод
Для реализации связи многие ко многим нам нужен некий посредник между двумя рассматриваемыми таблицами. Он должен хранить два внешних ключа, первый из которых ссылается на первую таблицу, а второй — на вторую.
5. Один ко многим
Эта самая распространенная связь между базами данных. Мы рассматриваем ее после связи многие ко многим для сравнения.
Предположим, нам нужно реализовать некую БД, которая ведет учет данных о пользователях. У пользователя есть: имя, фамилия, возраст, номера телефонов. При этом у каждого пользователя может быть от одного и больше номеров телефонов (многие номера телефонов).
В этом случае мы наблюдаем следующее: пользователь может иметь многие номера телефонов, но нельзя сказать, что номеру телефона принадлежит определенный пользователь.
Другими словами, телефон принадлежит только одному пользователю. А пользователю могут принадлежать 1 и более телефонов (многие).
Как мы видим, это отношение один ко многим.
5.1. Как построить такие таблицы?
Пользователей будет представлять некая таблица «Person» (id, имя, фамилия, возраст), номера телефонов будет представлять таблица «Phone». Она будет выглядеть так:
| PhoneId | PersonId | PhoneNumber |
|---|---|---|
| 1 | 5 | 11 091-10 |
| 2 | 5 | 19 124-66 |
| 3 | 17 | 21 972-02 |
Данная таблица представляет три номера телефона. При этом номера телефона с id 1 и 2 принадлежат пользователю с id 5. А вот номер с id 3 принадлежит пользователю с id 17.
Заметка. Если бы у таблицы «Phones» было бы больше атрибутов, то мы смело бы их добавляли в эту таблицу.
5.2. Почему мы не делаем тут таблицу-посредника?
Таблица-посредник нужна только в том случае, если мы имеем связь многие-ко-многим. По той простой причине, что мы можем рассматривать ее с двух сторон. Как, например, таблицу EmployeesPositions ранее:
- Каждому работнику принадлежат несколько должностей (многие).
- Каждой должности принадлежит несколько работников (многие).
5.3. Реализация

Наша таблица Phone хранит всего один внешний ключ. Он ссылается на некого пользователя (на строку из таблицы Person). Таким образом, мы как бы говорим: «этот пользователь является владельцем данного телефона». Другими словами, телефон знает id своего владельца.
6. Один к одному
Представим, что на работе вам дали задание написать БД для учета всех работников для HR. Начальник уверял, что компании нужно знать только об имени, возрасте и телефоне работника. Вы разработали такую БД и поместили в нее всю 1000 работников компании. И тут начальник говорит, что им зачем-то нужно знать о том, является ли работник инвалидом или нет. Наиболее простое, что приходит в голову — это добавить новый столбец типа bool в вашу таблицу. Но это слишком долго вписывать 1000 значений и ведь true вы будете вписывать намного реже, чем false (2% будут true, например).
Более простым решением будет создать новую таблицу, назовем ее «DisabledEmployee». Она будет выглядеть так:
Но это еще не связь один к одному. Дело в том, что в такую таблицу работник может быть вписан более одного раза, соответственно, мы получили отношение один ко многим: работник может быть несколько раз инвалидом. Нужно сделать так, чтобы работник мог быть вписан в таблицу только один раз, соответственно, мог быть инвалидом только один раз. Для этого нам нужно указать, что столбец EmployeeId может хранить только уникальные значения. Нам нужно просто наложить на столбец EmloyeeId ограничение unique. Это ограничение сообщает, что атрибут может принимать только уникальные значения.
Выполнив это мы получили связь один к одному.
Заметка. Обратите внимание на то, что мы могли также наложить на атрибут EmloyeeId ограничение primary key. Оно отличается от ограничения unique лишь тем, что не может принимать значения null.
6.1. Вывод
Можно сказать, что отношение один к одному — это разделение одной и той же таблицы на две.
6.2. Реализация

Таблица DisabledEmployee имеет атрибут EmployeeId, что является внешним ключом. Он ссылается на атрибут EmployeeId таблицы Employee. Кроме того, этот атрибут имеет ограничение unique, что говорит о том, что в него могут быть записаны только уникальные значения. Соответственно, работник может быть записан в эту таблицу не более одного раза.
7. Обязательные и необязательные связи
Связи можно поделить на обязательные и необязательные.
7.1. Один ко многим
- Один ко многим с обязательной связью:
К одному полку относятся многие бойцы. Один боец относится только к одному полку. Обратите внимание, что любой солдат обязательно принадлежит к одному полку, а полк не может существовать без солдат. - Один ко многим с необязательной связью:
На планете Земля живут все люди. Каждый человек живет только на Земле. При этом планета может существовать и без человечества. Соответственно, нахождение нас на Земле не является обязательным
А) У женщины необязательно есть свои дети. Соответственно, связь необязательна.
Б) У ребенка обязательно есть только одна биологическая мать – в таком случае, связь обязательна.
7.2. Один к одному
- Один к одному с обязательной связью:
У одного гражданина определенной страны обязательно есть только один паспорт этой страны. У одного паспорта есть только один владелец. - Один к одному с необязательной связью:
У одной страны может быть только одна конституция. Одна конституция принадлежит только одной стране. Но конституция не является обязательной. У страны она может быть, а может и не быть, как, например, у Израиля и Великобритании.
У одного человека может быть только один загранпаспорт. У одного загранпаспорта есть только один владелец.
А) Наличие загранпаспорта необязательно – его может и не быть у гражданина. Это необязательная связь.
Б) У загранпаспорта обязательно есть только один владелец. В этом случае, это уже обязательная связь.
7.3. Многие ко многим
Человек может инвестировать в акции разных компаний (многих). Инвесторами какой-то компании являются определенные люди (многие).
А) Человек может вообще не инвестировать свои деньги в акции.
Б) Акции компании мог никто не купить.
8. Как читать диаграммы?
Выше я приводил диаграммы созданных нами таблиц. Но для того, чтобы их понимать, нужно знать, как их «читать». Разберемся в этом на примере диаграммы из пункта 5.3.
Мы видим отношение один ко многим. Одной персоне принадлежит много телефонов.
The vertical toolbar on the left side of an EER Diagram has six foreign key tools:
one-to-one non-identifying relationship
one-to-many non-identifying relationship
one-to-one identifying relationship
one-to-many identifying relationship
many-to-many identifying relationship
Place a Relationship Using Existing Columns
An identifying relationship : identified by a solid line between tables
An identifying relationship is one where the child table cannot be uniquely identified without its parent. Typically this occurs where an intermediary table is created to resolve a many-to-many relationship. In such cases, the primary key is usually a composite key made up of the primary keys from the two original tables.
A non-identifying relationship : identified by a broken (dashed) line between tables
Create or drag and drop the tables that you wish to connect. Ensure that there is a primary key in the table that will be on the “ one ” side of the relationship. Click on the appropriate tool for the type of relationship you wish to create. If you are creating a one-to-many relationship, first click the table that is on the “ many ” side of the relationship, then on the table containing the referenced key. This creates a column in the table on the many side of the relationship. The default name of this column is table_name_key_name where the table name and the key name both refer to the table containing the referenced key.
When the many-to-many tool is active, double-clicking a table creates an associative table with a many-to-many relationship. For this tool to function there must be a primary key defined in the initial table.
Use the Model menu, Menu Options menu item to set a project-specific default name for the foreign key column (see Section 9.1.1.1.5.4, “The Relationship Notation Submenu”). To change the global default, see Section 3.2.4, “Modeling Preferences”.
To edit the properties of a foreign key, double-click anywhere on the connection line that joins the two tables. This opens the relationship editor.
Pausing your mouse pointer over a relationship connector highlights the connector and the related keys as shown in the following figure. The film and the film_actor tables are related on the film_id field and these fields are highlighted in both tables. Since the film_id field is part of the primary key in the film_actor table, a solid line is used for the connector between the two tables. After pausing over a relationship for a second, a yellow box is displayed that provides additional information.
Figure 9.16 The Relationship Connector

If the placement of a connection's caption is not suitable, you can change its position by dragging it to a different location. If you have set a secondary caption, its position can also be changed. For more information about secondary captions, see Section 9.1.4.3, “Connection Properties”. Where the notation style permits, Classic for example, the cardinality indicators can also be repositioned.
The relationship notation style in Figure 9.16, “The Relationship Connector” is the default, crow's foot. You can change this if you are using a Commercial Edition of MySQL Workbench. For more information, see Section 9.1.1.1.5.4, “The Relationship Notation Submenu”.
You can select multiple connections by holding down the Control key as you click a connection. This can be useful for highlighting specific relationships on an EER diagram.
Внимание, поскольку WorkBench обновился, то я написал новую статью, которая состоит из теории и практики построения БД из WorkBench.
Итак, в прошлом посте, мы создали физическую базу данных и первую таблицу в базе данных, при помощи программы MySQL Workbench (в дословном переводе “Рабочая скамья” )))).
В этом посте мы узнаем, что такое модели в программе WorkBench и как с их помощью создавать взаимосвязанные таблицы (с внешними ключами), а заодно – усовершенствуем нашу базу данных для последующих экспериментов. Предыдущим методом мы могли из Workbench создавать только базу данных и какие-то отдельные таблицы.
Итак, в программе MySQL WorkBench жмем File New Model (Ctrl + N) и перед нами открывается такая картина…
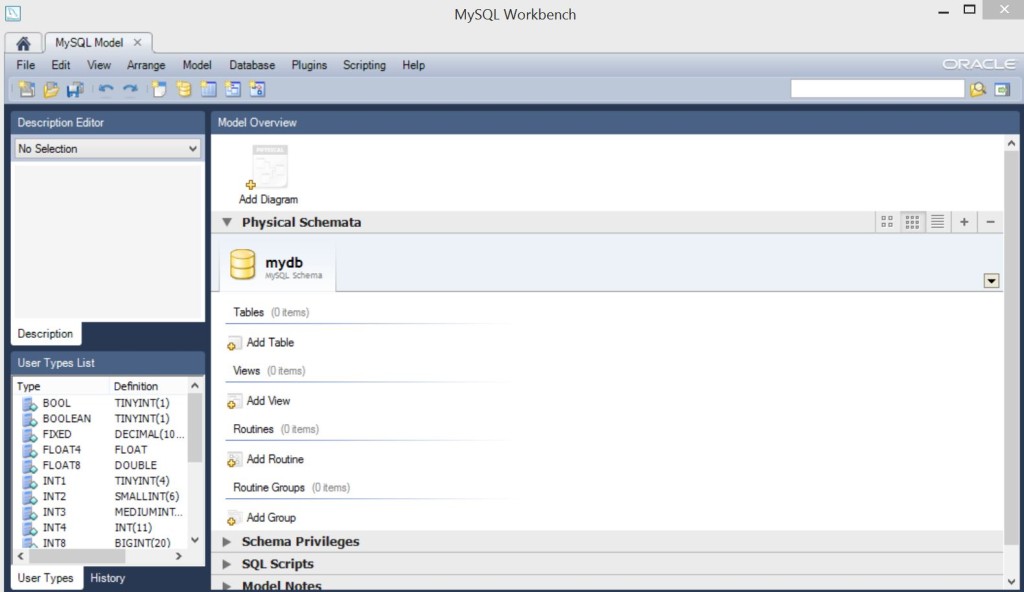
Итак, все, что мы создадим сейчас будет называться моделью, программа поможет нам сформировать скрипт, который и создаст реальную базу данных.
1 Создание базы данных (схемы) в модели
Итак, начнем, с редакции имени базы данных. Терминологическое отступление. Вообще база данных ещё называется “Schema”, это синонимы, насколько я помню из книги Д. Осипова, “Базы данных и Delphi”, это произошло не сразу, а после очередного собрания “стандартизаторов” баз данных. Чтобы отредактировать название “Схемы”, нужно проделать следующее…
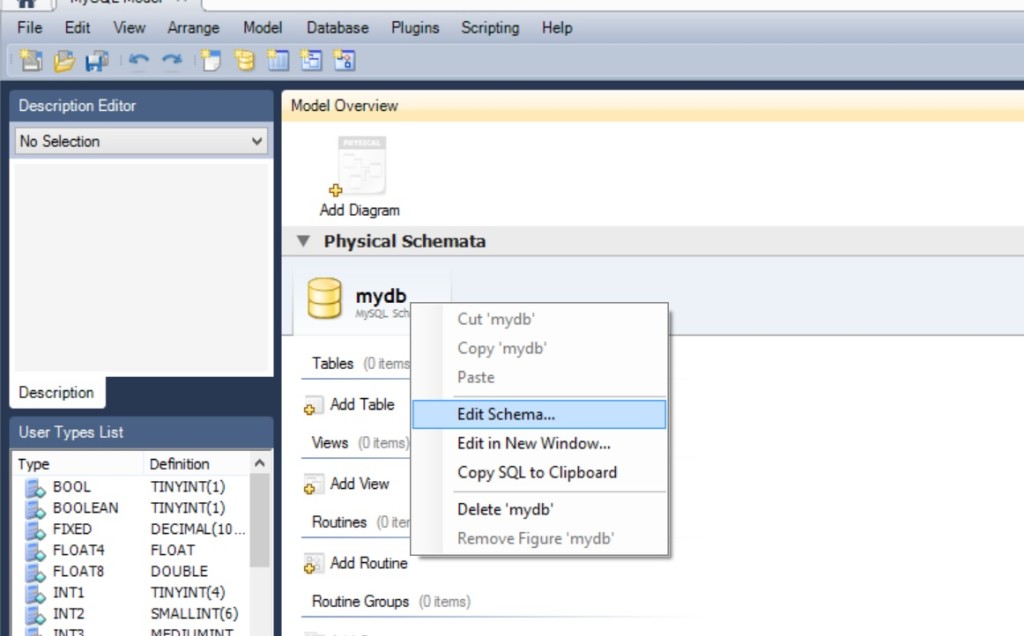
Перед нами открывается такое окно…
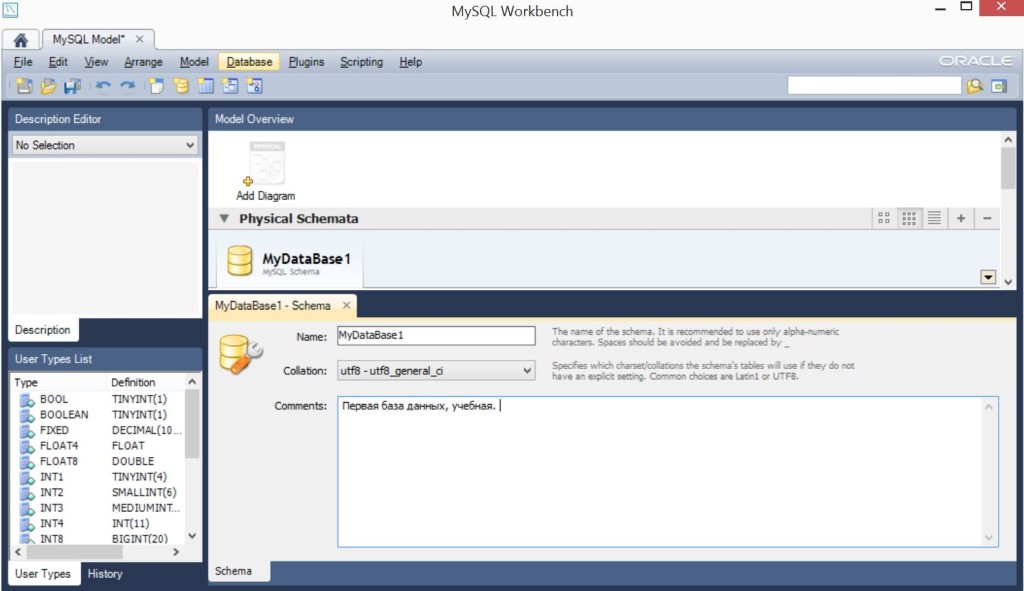
Я назвал базу данных, схему – MyDataBase1, кодировку не менял, в комментарии указал – “Первая база данных, учебная”;
После этого – жмём на крестик, на вкладке возле названия “MyDataBase1” и возвращаемся к предыдущему окну.
2 Создание таблиц в базе данных (схеме)
Итак, для того, чтобы создать таблицы – нам нужно определиться какую ситуацию будет отражать база данных. Я предлагаю сделать всё на примере студентов – все учились, всем будет понятно.
Каждый студент учится на каком-то одном факультете, поэтому, для начала предлагаю создать таблицу “Students” и таблицу “Departments”…
2 раза кликаем на AddTable и видим такую картину… Заполняем поле Table Name…
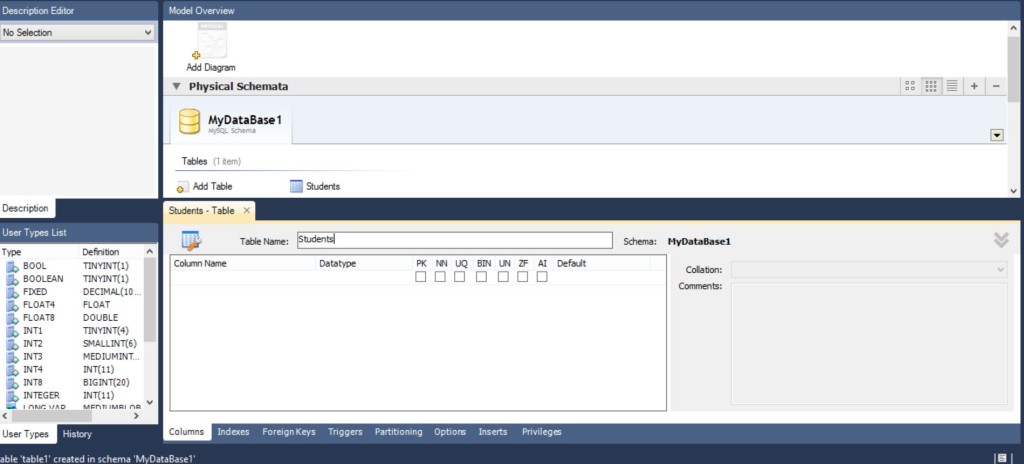
Заполняем имя таблицы. Обратите внимание на вкладки внизу, сейчас мы находимся на “Coloumns”. Для таблицы студентов разработаем несколько полей…
-Primary_key (уникальный ключ записей данной таблицы)
-Department_id (Внешний ключ, каждый студент учится на каком-то факультете, соответственно будем отмечать это в данном поле);
И сразу же введём их, на вкладке Students -Table – Coloumns, результат получился такой…
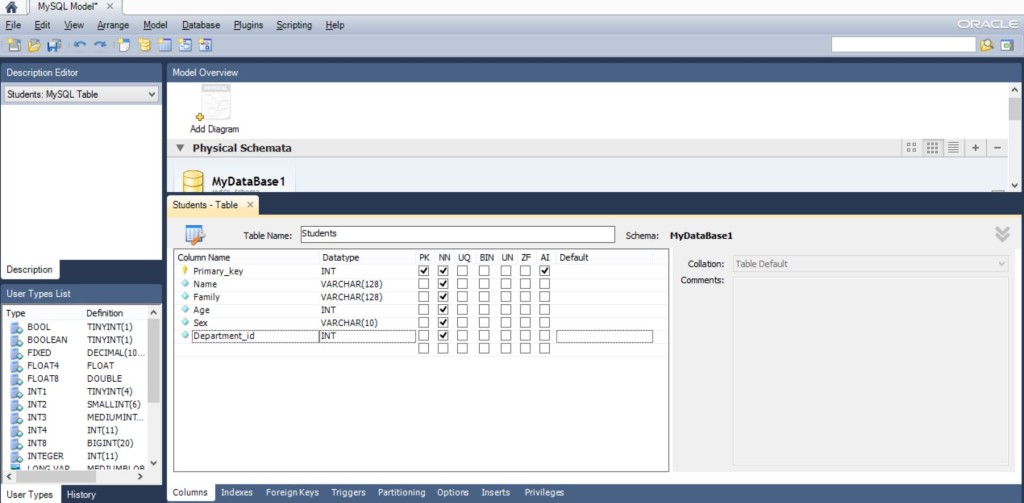
Итак, “PK” – поставил только у главного ключа, это поле является частью формирования уникального ключа таблицы (насколько я понял, в формировании такого ключа может участвовать несколько полей, но это в дальнейших исследованиях).
NN – Not Nulled – отсутствие нулевых полей, так как у всех студентов есть Имя, Фамилия, Возраст, Пол…
AI – автоинкрементное поле – с добавлением новой записи значение в этом поле будет увеличиваться как минимум на единицу.
Аналогично создадим и настроим таблицу Departments. В ней я создал 2 поля Primary_key и Department_name, в терминологии баз данных, получилось так..
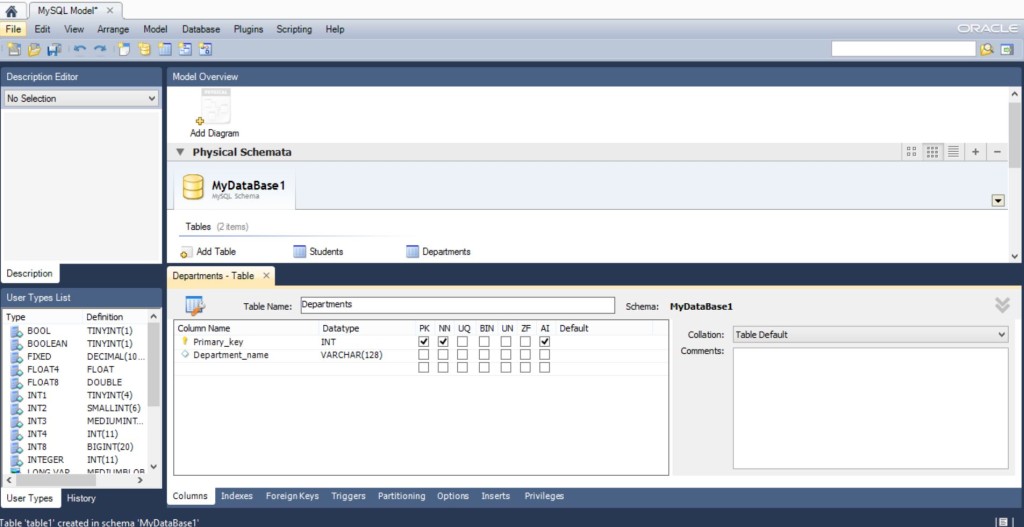
Здесь сделаю небольшое пояснение, Deparment_id в таблице students и Primary_key, в таблице departments это практически одно и тоже, разница лишь в том, что значения внешнего ключа Deparment_id разбросаны по таблице, а Primary_key автоинкрементен в своей таблице.
3 Стартовое заполнение созданных таблиц
Для того, чтобы нам с Вами делать какие-то дальнейшие эксперименты с IDE Delphi, языком SQL и др. вещами – нужно сделать стартовое заполнение, то есть, внести хоть какие-то записи. Для этого, на каждой из таблиц переходим во вкладку Inserts. Она внизу….
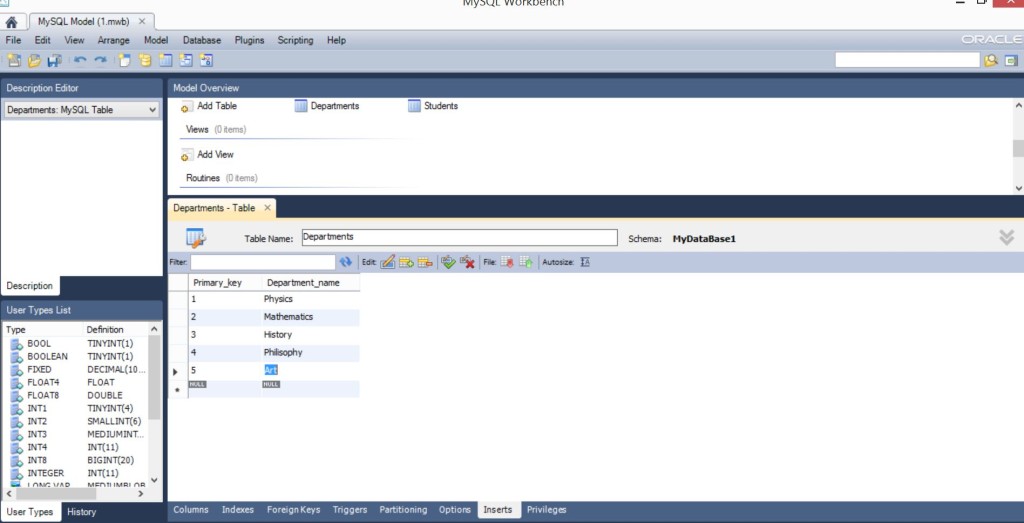
Для таблицы Departments – я сделал 5 факультетов – Physics, Mathematics, History, Philosophy, Art.
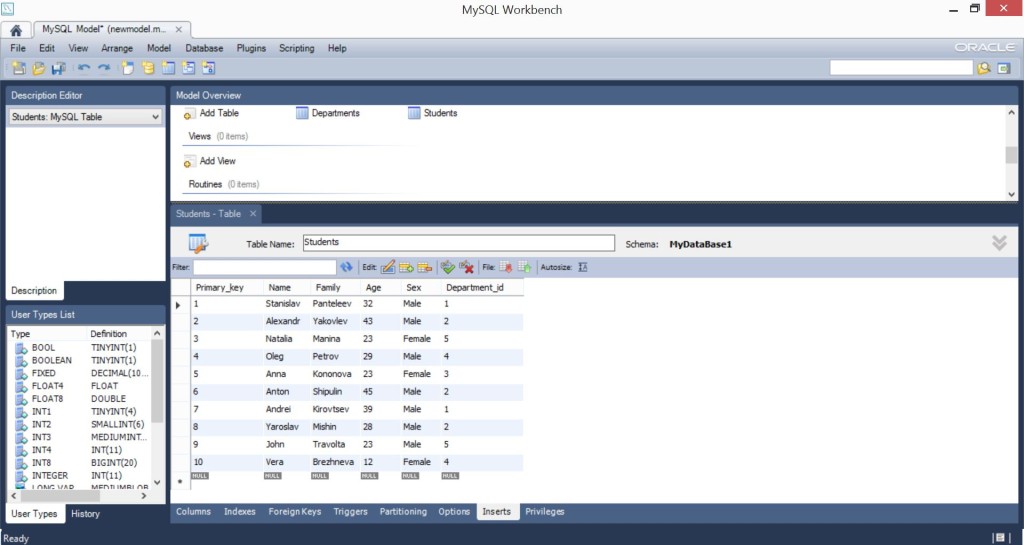
Для таблицы Students 10 произвольных записей. Если будете повторять пример – можете написать, что угодно, главное, соблюдать тип данных и в автоинкрементных полях писать по порядку.
После ввода записей, не забывайте нажать “Apply Updates”
Создание связи между таблицами
Для создания связи между таблицами, сначала разберемся в типе связи. В нашей ситуации на одном факультете может учиться несколько студентов, значит связь – один ко многим. Открываем вкладку Foreign Keys, дописываем “ручками” имя ключа, я написал “MyForeignKey1”, в Referenced table выбрал Departments, а в правой части таблицы – выбрал в колонке Coloumn Department_id, поскольку это было имя внешнего ключа для таблицы Students и соответствующее поле в другой таблице Primary Key
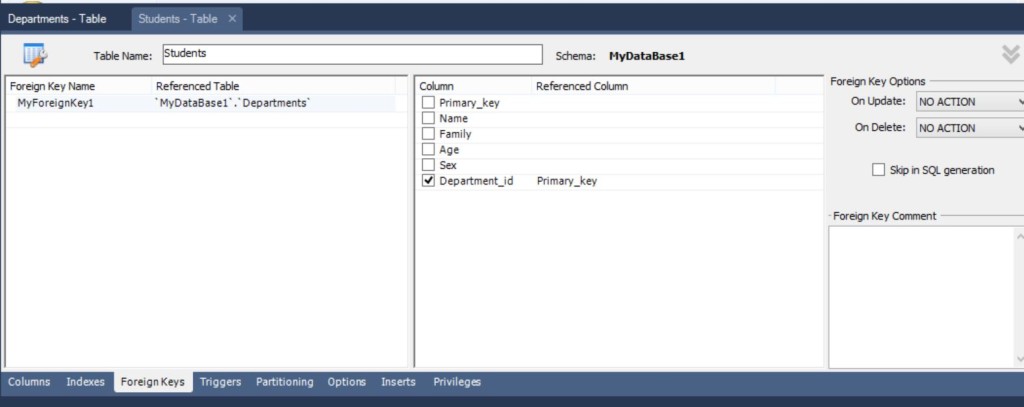
Можно также ещё заполнить Foreign Key Options. По описанию из блога Mithandrir
В разделе “Foreign Key Options” настраиваем поведение внешнего ключа при изменении соответствующего поля (ON UPDATE) и удалении (ON DELETE) родительской записи:
- RESTRICT – выдавать ошибку при изменении / удалении родительской записи
- CASCADE – обновлять внешний ключ при изменении родительской записи, удалять дочернюю запись при удалении родителя
- SET NULL – устанавливать значение внешнего ключа NULL при изменении / удалении родителя (неприемлемо для полей, у которых установлен флаг NOT NULL!)
- NO ACTION – не делать ничего, однако по факту эффект аналогичен RESTRICT
Сохранение из модели в реальную / физическую базу данных
“File → Export→ Forward Engineer MySQL Create Script…”
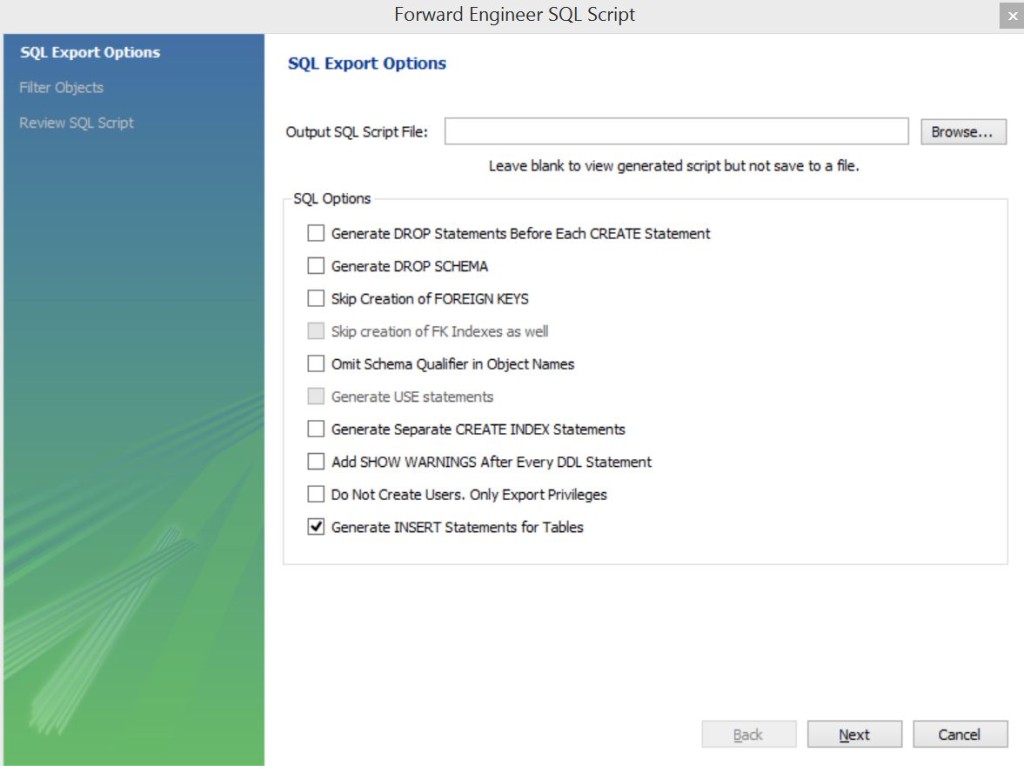
Отмечаем необходимые галочки, мне нужна была только одна Generate INSERT Statements for Tables. Если нужно сохранить скрипт в файл – пропишите директорию в поле сверху.
В следующем окне можно настроить – какие объекты мы будем экспортировать. Если внимательно присмотреться, то у нас создано всего 2 таблицы.
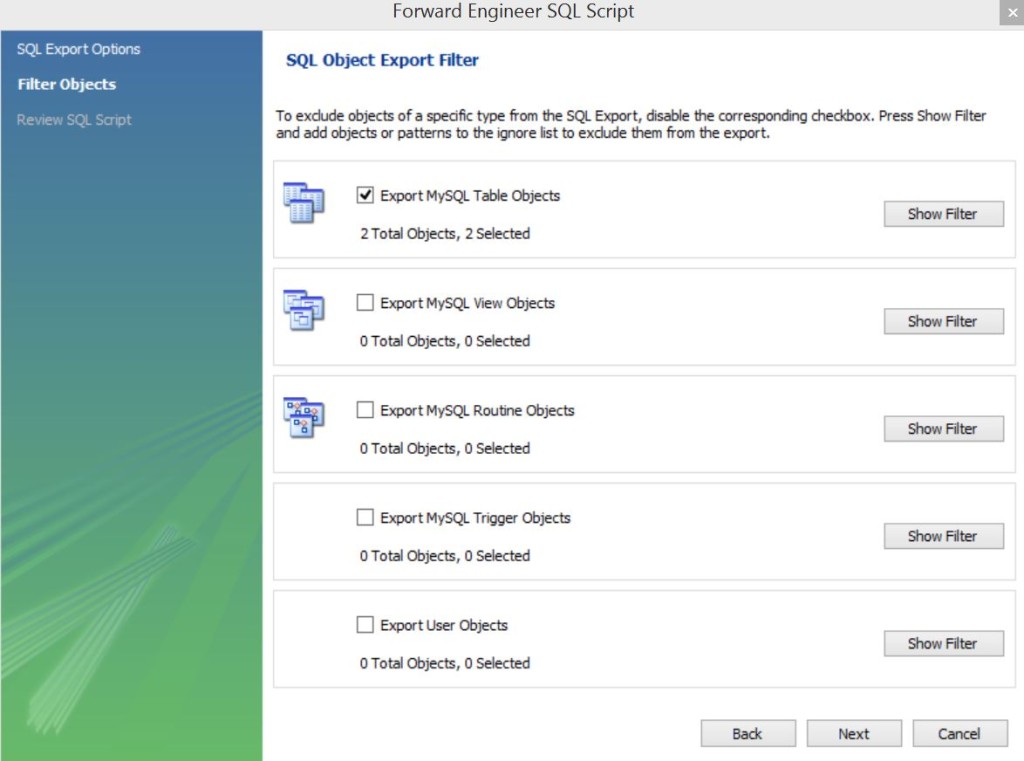
Жмем далее… и получаем такой вот скрипт…
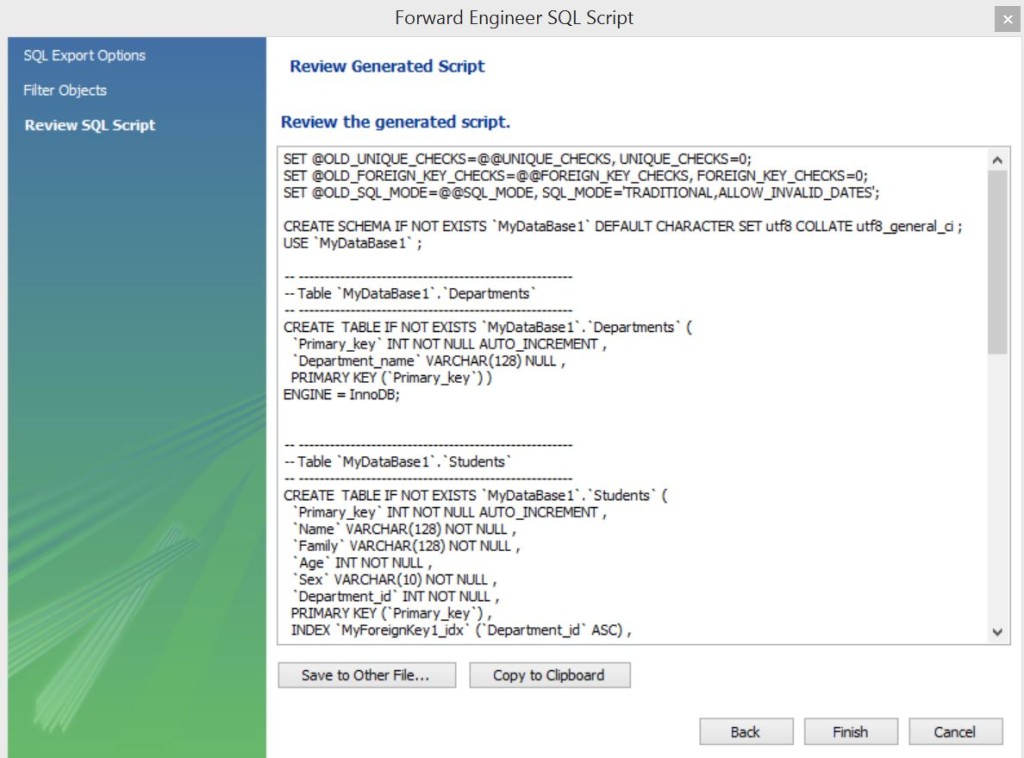
Копируем в буфер, но что дальше? Нужно этот скрипт где-то выполнить…
Выполнение скрипта – создания базы данных и таблиц
Жмем на “домик” в верхнем левом углу программы…
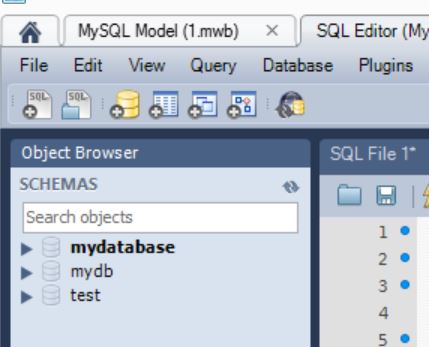
Потом 2 раза кликаем на MyConnection….
Перед нами открывается такая вкладка…
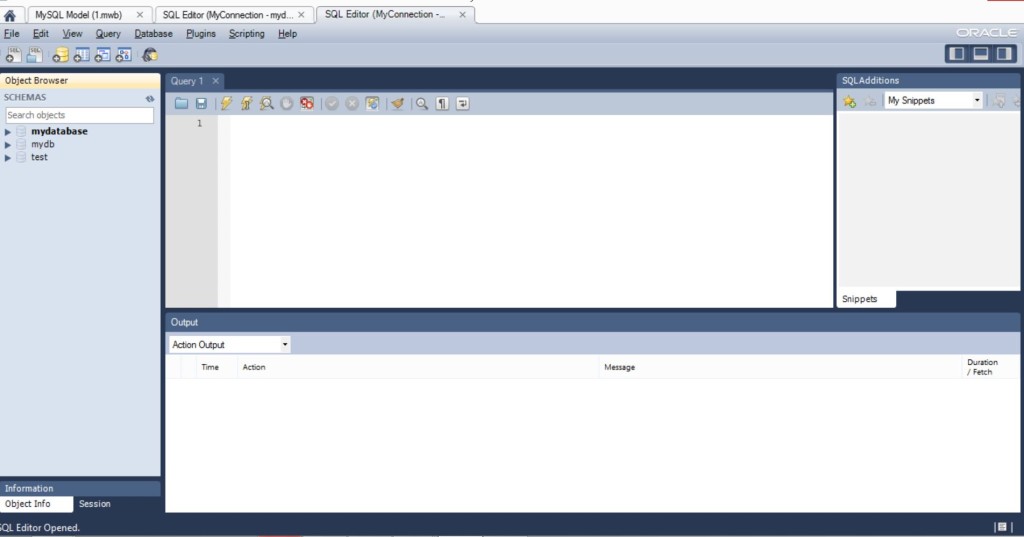
Это наше соединение с сервером, здесь мы и будем выполнять наш скрипт. Обратите внимание, слева базы данных, которые были созданы в программе WorkBench….
Далее, File New Query Tab… Вставляем скрипт в полученный Tab…
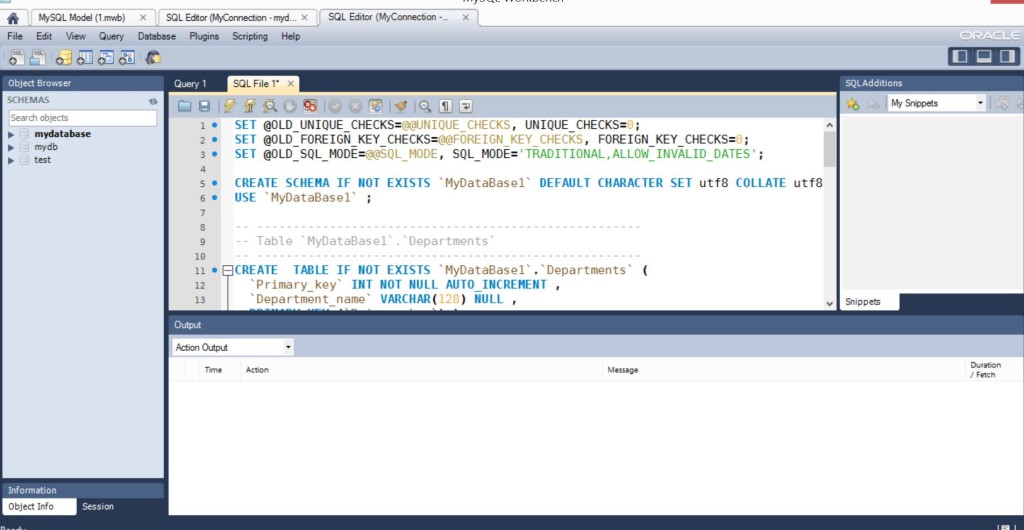
Теперь, нужно дать команду этот скрипт исполнить, для этого жмем в верхнем меню, Query Execute (All or Selection)
Итак, если все нормально, то в нижнем окне output, вы увидите все “зеленые галочки”. А когда нажмете Refresh в контекстном меню в списке баз данных, то увидите, вновь созданную базу mydatabase1.
Напоследок, построим ER диаграмму. ER расшифровывается как Entity Relation – удачная модель “Сущность – связь”, которая, в частности разрабатывалась Питером Ченом. Итак, возвращаемся на вкладку модели и жмем на Add Diagramm…
Далее, переносим таблицы в область диаграммы…
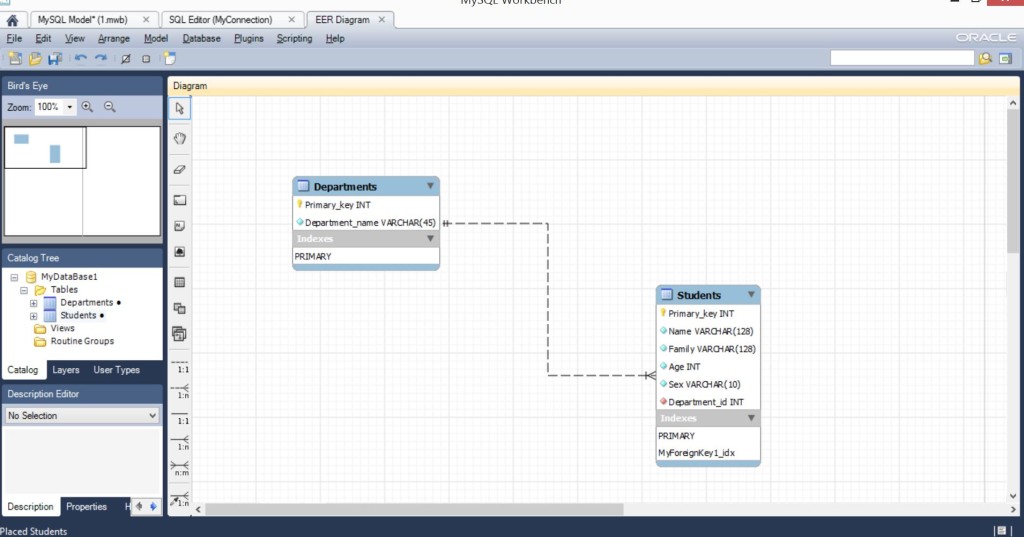
Мы создали связь один ко многим. На одном факультете могут учиться несколько студентов. Обратите внимание, связь возле таблицы Students расщепляется – это означает “ко многим”.
Итак, мы создали модель, из неё через выполнение скрипта – реальную базу с таблицами. А также создали диаграмму ER.
Читайте также: