
Как связать таблицы в mysql
Обновлено: 26.07.2024
MySQL - это реляционная база данных. Это означает, что данные в базе могут быть распределены в нескольких таблицах, и связаны друг с другом с помощью отношений (relation). Отсюда и название - реляционные.
Связи между таблицами происходят с помощью ключей. К примеру, в созданной нами ранее таблице пользователей есть первичный ключ - поле id. Если мы захотим сделать таблицу со статьями и хранить в ней авторов этих статей, то мы можем добавить новый столбец author_id и хранить в нём id пользователей из таблицы users.
Это был лишь один из примеров. Всего же типов подобных связей может быть 3:
- один-к-одному;
- один-ко-многим;
- многие-ко-многим.
Давайте же рассмотрим пример каждой из этих связей.
Один-к-одному
При связи один-к-одному каждой записи таблицы соответствует только одна запись в другой таблице.
Давайте заведем ещё одну таблицу, в которой будет храниться профиль пользователя. В нём можно будет указать информацию о себе и ссылку на профиль в VKontakte.
Добавим для каждого пользователя профиль:
Посмотрим на получившиеся профили:

Теперь каждой записи из таблицы users соответствует только одна запись из таблицы users_profiles и наоборот.
INNER JOIN
Прежде чем идти дальше и рассматривать другие типы связей, стоит изучить ещё один оператор SQL - INNER JOIN. Он используется для объединения строк из двух и более таблиц, основываясь на отношениях между ними. Для запроса используется следующий синтаксис:
Чтобы получить всех пользователей вместе с их профилями нам нужно выполнить следующий запрос:

Каждая строка из левой таблицы, сопоставляется с каждой строкой из правой таблицы, после этого проверяется условие.
Если мы хотим выбрать только некоторые столбцы, то после оператора SELECT нужно перед именем поля явно указать название таблицы, из которой оно берется:

Алиасы
Согласитесь, в прошлом примере пришлось довольно много букв написать. Чтобы этого избежать, в запросах можно использовать алиасы для имён таблиц. Для этого после имени таблицы можно написать AS alias. Давайте для таблицы users зададим алиас - u, а для таблицы profiles - p. Эти алиасы теперь можно использовать в любой части запроса:
Заметьте, запрос сократился. Писать запрос с использованием алиаса быстрее.

Один-ко-многим
При такой связи одной записи в одной таблице соответствует несколько записей в другой. В начале этого урока мы рассмотрели как раз такой пример, когда говорили о добавлении в таблицу с новостями поля author_id. Таким образом, у каждой статьи есть один автор. В то же время у одного автора может быть несколько статей.
Давайте создадим таблицу для статей. Пусть в ней будет идентификатор статьи, её название, текст, и идентификатор автора.
Добавим несколько статей:
Запросим теперь эти записи, чтобы убедиться, что всё ок

Давайте теперь выведем имена статей вместе с авторами. Для этого снова воспользуемся оператором INNER JOIN.

Как видим, у Ивана две статьи, и ещё одна у Ольги.
Если бы мы захотели на странице со статьей выводить рядом с автором краткую информацию о нем, нам нужно было бы сделать ещё один JOIN на табличку profiles.

LEFT JOIN
Помимо INNER JOIN, есть ещё несколько операторов класса JOIN. Один из самых частоиспользуемых - LEFT JOIN. Он позволяет сделать запрос к двум таблицам, между которыми есть связь, и при этом для одной из таблиц вернуть записи, даже если они не соответствуют записям в другой таблице.
Как например, если бы мы хотели вывести не только пользователей, у которых есть статьи, но и тех, кто "халтурит" :)
Давайте для начала сделаем запрос с использованием INNER JOIN, который выведет пользователей и написанные ими статьи:

Теперь заменим INNER JOIN на LEFT JOIN:

Видите, вывелись записи из левой таблицы (users), которым не соответствует при этом ни одна запись из правой таблицы (articles).
Многие-ко-многим
Такая связь возникает, когда множество строк одной таблицы соответствуют множеству строк другой таблицы. Чтобы связать их между собой, нужно создать третью таблицу, создав с каждой из первых двух связь один-ко-многим.
В качестве примера такой связи можно привести рубрики статей. Каждая статья может иметь несколько рубрик. И одновременно с этим, каждая рубрика может содержать в себе несколько статей. Давайте добавим таблицу для рубрик.
И сразу добавим в неё несколько рубрик.
Проверим, что они добавились.

Теперь нам нужно добавить ещё одну таблицу, в которой будут храниться связи между article.id и category.id. Создаём:
Обратите внимание на составной первичный ключ. Здесь нам требуется, чтобы именно пара (id_статьи - id_рубрики) была уникальной. А сами по себе значения в отдельных колонок могут повторяться.
Связи — это довольна важная тема, которую следует понимать при проектировании баз данных. По своему личному опыту скажу, что осознав связи, мне намного легче далось понимание нормализации базы данных.
1.1. Для кого эта статья?
Эта статья будет полезна тем, кто хочет разобраться со связями между таблицами базы данных. В ней я постарался рассказать на понятном языке, что это такое. Для лучшего понимания темы, я чередую теоретический материал с практическими примерами, представленными в виде диаграммы и запроса, создающего нужные нам таблицы. Я использую СУБД Microsoft SQL Server и запросы пишу на T-SQL. Написанный мною код должен работать и на других СУБД, поскольку запросы являются универсальными и не используют специфических конструкций языка T-SQL.
1.2. Как вы можете применить эти знания?
- Процесс создания баз данных станет для вас легче и понятнее.
- Понимание связей между таблицами поможет вам легче освоить нормализацию, что является очень важным при проектировании базы данных.
- Разобраться с чужой базой данных будет значительно проще.
- На собеседовании это будет очень хорошим плюсом.
2. Благодарности
Учтены были советы и критика авторов jobgemws, unfilled, firnind, Hamaruba.
Спасибо!
3.1. Как организовываются связи?
Связи создаются с помощью внешних ключей (foreign key).
Внешний ключ — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
3.2. Виды связей
Связи делятся на:
- Многие ко многим.
- Один ко многим.
- с обязательной связью;
- с необязательной связью;
- Один к одному.
- с обязательной связью;
- с необязательной связью;
4. Многие ко многим
Представим, что нам нужно написать БД, которая будет хранить работником IT-компании. При этом существует некий стандартный набор должностей. При этом:
- Работник может иметь одну и более должностей. Например, некий работник может быть и админом, и программистом.
- Должность может «владеть» одним и более работников. Например, админами является определенный набор работников. Другими словами, к админам относятся некие работники.
4.1. Как построить такие таблицы?
Мы уже имеем две таблицы, описывающие работника и профессию. Теперь нам нужно установить между ними связь многие ко многим. Для реализации такой связи нам нужен некий посредник между таблицами «Employee» и «Position». В нашем случае это будет некая таблица «EmployeesPositions» (работники и должности). Эта таблица-посредник связывает между собой работника и должность следующим образом:
Слева указаны работники (их id), справа — должности (их id). Работники и должности на этой таблице указываются с помощью id’шников.
На эту таблицу можно посмотреть с двух сторон:
- Таким образом, мы говорим, что работник с id 1 находится на должность с id 1. При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
- Мы также можем сказать, что должности с id 3 принадлежат пользователи с id 2 и 3. Т.е., каждой роли справа принадлежит некий работник слева.
4.2. Реализация

С помощью ограничения foreign key мы можем ссылаться на primary key или unique другой таблицы. В этом примере мы
- ссылаемся атрибутом PositionId таблицы EmployeesPositions на атрибут PositionId таблицы Position;
- атрибутом EmployeeId таблицы EmployeesPositions — на атрибут EmployeeId таблицы Employee;
4.3. Вывод
Для реализации связи многие ко многим нам нужен некий посредник между двумя рассматриваемыми таблицами. Он должен хранить два внешних ключа, первый из которых ссылается на первую таблицу, а второй — на вторую.
5. Один ко многим
Эта самая распространенная связь между базами данных. Мы рассматриваем ее после связи многие ко многим для сравнения.
Предположим, нам нужно реализовать некую БД, которая ведет учет данных о пользователях. У пользователя есть: имя, фамилия, возраст, номера телефонов. При этом у каждого пользователя может быть от одного и больше номеров телефонов (многие номера телефонов).
В этом случае мы наблюдаем следующее: пользователь может иметь многие номера телефонов, но нельзя сказать, что номеру телефона принадлежит определенный пользователь.
Другими словами, телефон принадлежит только одному пользователю. А пользователю могут принадлежать 1 и более телефонов (многие).
Как мы видим, это отношение один ко многим.
5.1. Как построить такие таблицы?
Пользователей будет представлять некая таблица «Person» (id, имя, фамилия, возраст), номера телефонов будет представлять таблица «Phone». Она будет выглядеть так:
| PhoneId | PersonId | PhoneNumber |
|---|---|---|
| 1 | 5 | 11 091-10 |
| 2 | 5 | 19 124-66 |
| 3 | 17 | 21 972-02 |
Данная таблица представляет три номера телефона. При этом номера телефона с id 1 и 2 принадлежат пользователю с id 5. А вот номер с id 3 принадлежит пользователю с id 17.
Заметка. Если бы у таблицы «Phones» было бы больше атрибутов, то мы смело бы их добавляли в эту таблицу.
5.2. Почему мы не делаем тут таблицу-посредника?
Таблица-посредник нужна только в том случае, если мы имеем связь многие-ко-многим. По той простой причине, что мы можем рассматривать ее с двух сторон. Как, например, таблицу EmployeesPositions ранее:
- Каждому работнику принадлежат несколько должностей (многие).
- Каждой должности принадлежит несколько работников (многие).
5.3. Реализация

Наша таблица Phone хранит всего один внешний ключ. Он ссылается на некого пользователя (на строку из таблицы Person). Таким образом, мы как бы говорим: «этот пользователь является владельцем данного телефона». Другими словами, телефон знает id своего владельца.
6. Один к одному
Представим, что на работе вам дали задание написать БД для учета всех работников для HR. Начальник уверял, что компании нужно знать только об имени, возрасте и телефоне работника. Вы разработали такую БД и поместили в нее всю 1000 работников компании. И тут начальник говорит, что им зачем-то нужно знать о том, является ли работник инвалидом или нет. Наиболее простое, что приходит в голову — это добавить новый столбец типа bool в вашу таблицу. Но это слишком долго вписывать 1000 значений и ведь true вы будете вписывать намного реже, чем false (2% будут true, например).
Более простым решением будет создать новую таблицу, назовем ее «DisabledEmployee». Она будет выглядеть так:
Но это еще не связь один к одному. Дело в том, что в такую таблицу работник может быть вписан более одного раза, соответственно, мы получили отношение один ко многим: работник может быть несколько раз инвалидом. Нужно сделать так, чтобы работник мог быть вписан в таблицу только один раз, соответственно, мог быть инвалидом только один раз. Для этого нам нужно указать, что столбец EmployeeId может хранить только уникальные значения. Нам нужно просто наложить на столбец EmloyeeId ограничение unique. Это ограничение сообщает, что атрибут может принимать только уникальные значения.
Выполнив это мы получили связь один к одному.
Заметка. Обратите внимание на то, что мы могли также наложить на атрибут EmloyeeId ограничение primary key. Оно отличается от ограничения unique лишь тем, что не может принимать значения null.
6.1. Вывод
Можно сказать, что отношение один к одному — это разделение одной и той же таблицы на две.
6.2. Реализация

Таблица DisabledEmployee имеет атрибут EmployeeId, что является внешним ключом. Он ссылается на атрибут EmployeeId таблицы Employee. Кроме того, этот атрибут имеет ограничение unique, что говорит о том, что в него могут быть записаны только уникальные значения. Соответственно, работник может быть записан в эту таблицу не более одного раза.
7. Обязательные и необязательные связи
Связи можно поделить на обязательные и необязательные.
7.1. Один ко многим
- Один ко многим с обязательной связью:
К одному полку относятся многие бойцы. Один боец относится только к одному полку. Обратите внимание, что любой солдат обязательно принадлежит к одному полку, а полк не может существовать без солдат. - Один ко многим с необязательной связью:
На планете Земля живут все люди. Каждый человек живет только на Земле. При этом планета может существовать и без человечества. Соответственно, нахождение нас на Земле не является обязательным
А) У женщины необязательно есть свои дети. Соответственно, связь необязательна.
Б) У ребенка обязательно есть только одна биологическая мать – в таком случае, связь обязательна.
7.2. Один к одному
- Один к одному с обязательной связью:
У одного гражданина определенной страны обязательно есть только один паспорт этой страны. У одного паспорта есть только один владелец. - Один к одному с необязательной связью:
У одной страны может быть только одна конституция. Одна конституция принадлежит только одной стране. Но конституция не является обязательной. У страны она может быть, а может и не быть, как, например, у Израиля и Великобритании.
У одного человека может быть только один загранпаспорт. У одного загранпаспорта есть только один владелец.
А) Наличие загранпаспорта необязательно – его может и не быть у гражданина. Это необязательная связь.
Б) У загранпаспорта обязательно есть только один владелец. В этом случае, это уже обязательная связь.
7.3. Многие ко многим
Человек может инвестировать в акции разных компаний (многих). Инвесторами какой-то компании являются определенные люди (многие).
А) Человек может вообще не инвестировать свои деньги в акции.
Б) Акции компании мог никто не купить.
8. Как читать диаграммы?
Выше я приводил диаграммы созданных нами таблиц. Но для того, чтобы их понимать, нужно знать, как их «читать». Разберемся в этом на примере диаграммы из пункта 5.3.
Мы видим отношение один ко многим. Одной персоне принадлежит много телефонов.
Я уже показал вам как данные из разных таблиц могут быть связаны при помощи связи по внешнему ключу. Вы видели как заказы связываются с клиентами путем помещения customer_id в качестве внешнего ключа в таблице заказов.
Другой пример связи один-ко-многим – это связь, которая существует между матерью и ее детьми. Мать может иметь множество детей, но каждый ребенок может иметь только одну мать.
(Технически лучше говорить о женщине и ее детях вместо матери и ее детях потому, что, в контексте связи один-ко-многим, мать может иметь 0, 1 или множество потомков, но мать с 0 детей не может считаться матерью. Но давайте закроем на это глаза, хорошо?)
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Как опознать связь один-ко-многим?
Если у вас есть две сущности спросите себя:
1) Сколько объектов и B могут относится к объекту A?
2) Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ – множество, а на второй – один (или возможно, что ни одного), то вы имеете дело со связью один-ко-многим.
Примеры.
Некоторые примеры связи один-ко-многим:
- Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
- Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
- Диаграмма сущность-связь и ее таблицы. Диаграмма может иметь больше, чем одну таблицу, но каждая из этих таблиц принадлежит только одной диаграмме.
- Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
В данном случае все настолько просто, что только поэтому может оказаться трудным понимание. Возьмем последний пример с домами. На улице ведь действительно может быть любое количество домов, но у каждого дома именно на этой улице может быть только одна улица (не берем дома, которые на практике принадлежат разным улицам, возьмем, к примеру, дом в центре улицы). Ведь не может конкретно этот дом быть одновременно в двух местах, на двух разных улицах, а мы говорим не про какой-то абстрактный дом вообще, а про конкретный.
8. Связь многие-ко-многим.
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Связь между поставщиком пива и пивом, которое они поставляют – это тоже связь многие-ко-многим. Поставщик, во многих случаях, предоставляет более одного вида пива, а каждый вид пива может быть предоставлен множеством поставщиков.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли определенные связи в данный момент, а о том, возможно ли существование связей вообще, в перспективе. Если в настоящий момент все поставщики предоставляют множество видов пива, но каждый вид пива предоставляется только одним поставщиком, то вы можете подумать, что это связь один-ко-многим, но… Не торопитесь реализовывать связь один-ко-многим в этой ситуации. Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиками и видами пива – не будет подготовлена к этому.
Создание связи многие-ко-многим.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проект базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в связи многие-ко-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и distributor_id уникальны в соединительной таблице.
Таблицы “о пиве”.

Таблицы выше связывают поставщиков и пиво связью многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво 'Gentse Tripel' (157) поставляют Horeca Import NL (157, AC001) Jansen Horeca (157, AB899) и Petersen Drankenhandel (157, AC009). И vice versa, Petersen Drankenhandel является поставщиком 3 видов пива из таблицы, а именно: Gentse Tripel (157, AC009), Uilenspiegel (158, AC009) и Jupiler (163, AC009).
Еще обратите внимание, что в таблицах выше поля первичных ключей окрашены в синий цвет и имеют подчеркивание. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей. Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь на которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
Другой пример связи многие-ко-многим: заказ билетов в отеле.
В качестве последнего примера позвольте мне показать как бы могла быть смоделирована таблица заказов номеров гостиницы посетителями.

Соединительная таблица связи многие-ко-многим имеет дополнительные поля.
В этом примере вы видите, что между таблицами гостей и комнат существует связь многие-ко-многим. Одна комната может быть заказана многими гостями с течением времени и с течением времени гость может заказывать многие комнаты в отеле. Соединительная таблица в данном случае является не классической соединительной таблицей, которая состоит только из двух внешних ключей. Она является отдельной сущностью, которая имеет связи с двумя другими сущностями.
Вы часто будете сталкиваться с такими ситуациями, когда совокупность двух сущностей будет являться новой сущностью.
9. Связь один-к-одному.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
В одной таблице.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В отдельных таблицах.
В редких случаях связь один-к-одному моделируется используя две таблицы. Такой вариант иногда необходим, чтобы преодолеть ограничения РСУБД или с целью увеличения производительности (например, иногда — это вынесение поля с типом данных blob в отдельную таблицу для ускорения поиска по родительской таблице). Или порой вы можете решить, что вы хотите разделить две сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
Примеры связи один-к-одному.
- Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.

Проект реляционной базы данных – это коллекция таблиц, которые перелинковываются (связываются) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами”. В следующих частях я покажу как нормализовать вашу базу данных.
Какой же вид связи вам нужен?
Примеры связей таблиц на практике. Когда какие-то данные являются уникальными для конкретного объекта, например, человек и номера его паспортов, то имеем дело со связью один-ко-многим. Т.е. в одной таблице мы имеем список неких людей, а в другой таблице у нас есть перечисление номеров паспортов этого человека (напр., паспорт страны проживания и загранпаспорт). И эта комбинация данных уникальная для каждого человека. Т.е. у каждого человека может быть несколько номеров паспортов, но у каждого паспорта может быть только один владелец. Итого: нужны две таблицы.
А если есть некие данные, которые могу быть присвоены любому человеку, то имеем дело со связью многие-ко-многим. Например, есть таблица со списком людей и мы хотим хранить информацию о том, какие страны посетил каждый человек. В данном случае имеется две сущности: люди и страны. Любой человек может посетить любое количество стран равно, как и любая страна может быть посещена любым человеком. Т.е., в данном случае, страна не является уникальными данными для конкретного человека и может использоваться повторно.
А когда у вас есть набор уникальных данных, которые имеют отношение только друг к другу, то храните все в одной таблице. Ваш выбор – связь один-к-одному. Например, у вас есть небольшая коллекция автомобилей и вы хотите хранить информацию о них (цвет, марка, год выпуска и пр.).
В этой заметке мы научимся создавать связи между таблицами в базе данных MySQL с помощью phpmyadmin. Если по какой-то причине вы не желаете использовать phpmyadmin, смотрите приведенные ниже SQL-запросы.
Почему же связи удобно держать в самой базе данных? Ведь эту задачу обычно решает так и само приложение? Все дело в ограничениях и действиях при изменении, которые можно наложить на связи.
Например, можно запретить удалять категорию, если с ней связана хотя б одна заметка. Или удалить все заметки, если удалена категория. Или установить NULL в связующее поле. В любом случае, с помощью связей повышается отказоустойчивость и надежность приложения.
Для начала, движок таблиц должен быть InnoDB . Только он поддерживает внешние ключи ( foreign key ). Если у вас таблицы MyISAM , почитайте как их конвертировать в InnoDB .
Для того, чтобы связать таблицы по полям, необходимо сначала добавить в индекс связываемые поля:
В phpmyadmin выбираем таблицу, выбираем режим структуры, выделяем поле, для которого будем делать внешнюю связь и кликаем Индекс.
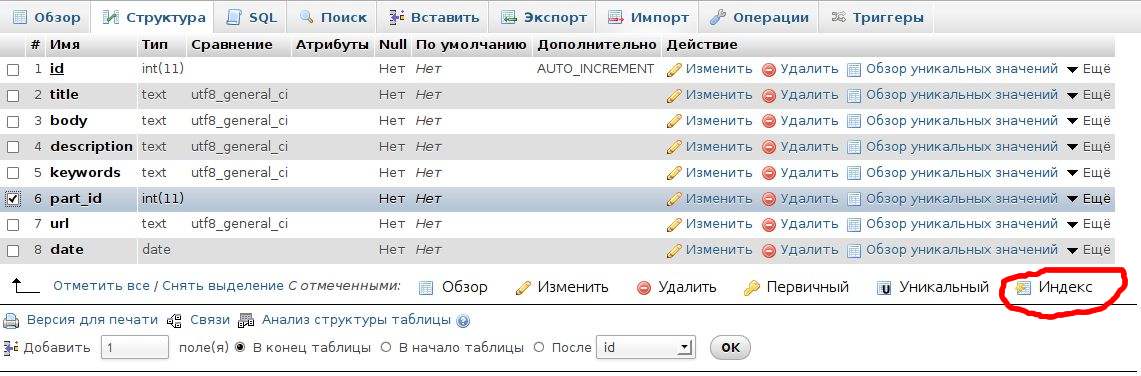
Обратите внимание на разницу между "Индекс" и "Уникальный". Уникальный индекс можно использовать, например, до поля id, то есть там, где значения не повторяются.
Это же действие можно сделать с помощью SQL-запроса:
Аналогично добавляем индекс (только в моем случае теперь уже уникальный или первичный) для таблицы, на которую ссылаемся, для поля id. Поскольку поле id у меня идентификатор, для него делаем первичный ключ. Уникальный ключ мог бы понадобится для других уникальных полей.
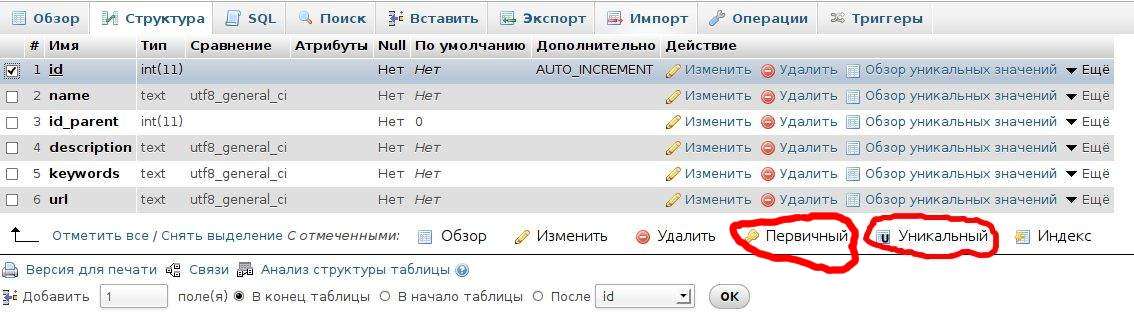
С помощью SQL-запроса:
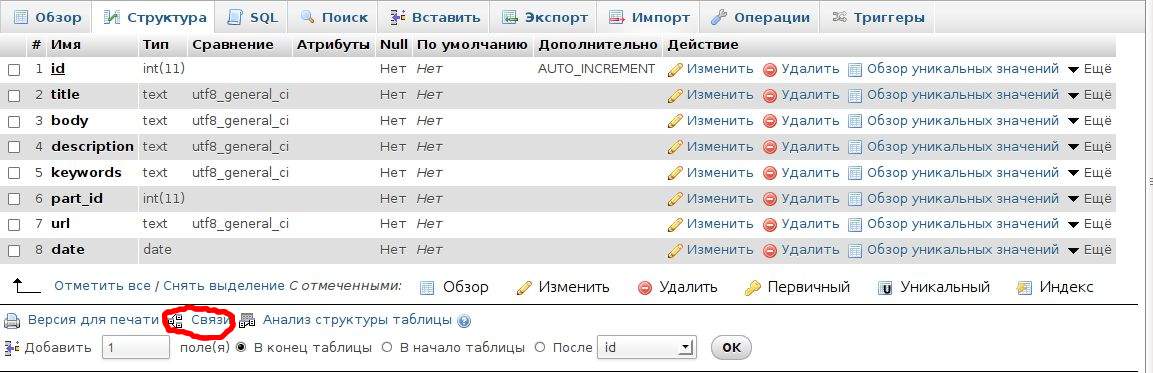
Теперь осталось только связать таблицы. Для этого кликаем внизу на пункт Связи:
Теперь для доступных полей (а доступны только проиндексированные поля) выбираем связь с внешними таблицами и действия при изменении записей в таблицах:
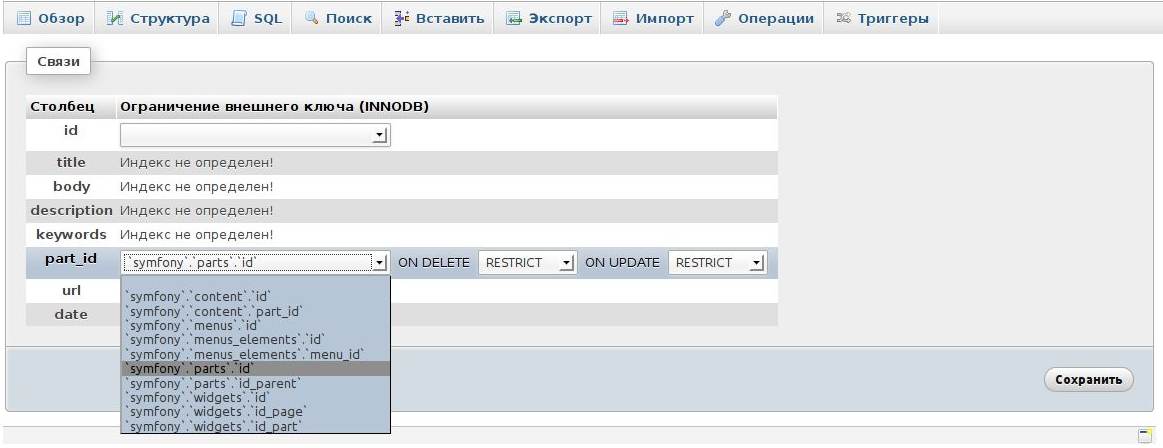
Через SQL-запрос:
Один ко многим (one-to-many)

Вспомним наш пример со странами и городами. Ясно, что у города должна быть страна. А как привязать страну к городу? Нужно к каждому городу прикрепить уникальный идентификатор (ID) страны, к которой он принадлежит: мы уже это делали. Это и называется одним из типов связей — один ко многим (еще хорошо бы знать английскую версию —one-to-many). Перефразируя, можно сказать: к одной стране может относиться несколько городов. Так и следует запоминать это: связь один ко многим. Пока что понятно, да? Если не очень, то вот первая картинка из интернетов:Здесь показано, что есть заказчики и их заказы. Ведь разумно, что у одного заказчика может быть больше одного заказа. Налицо one-to-many :) Или другой пример: Есть три таблицы: издатель, автор и книга. У каждого издателя, который не хочет обанкротиться и жаждет быть успешным, есть больше одного автора, согласны? В свою очередь, у каждого автора может быть больше одной книги — тут тоже сомнений быть не может. А это значит, опять-таки, связь один автор ко многим книгам, один издатель ко многим авторам . Примеров можно еще привести великое множество. Сложность в восприятии вначале может заключаться только в том, чтобы научиться абстрактно мыслить: смотреть со стороны на таблицы и их взаимодействие.
Один к одному (one-to-one)
Это, можно сказать, частный случай связи один-ко-многим. Ситуация, в которой одна запись в одной таблице связана только с одной записью в другой таблице. Какие могут быть примеры из жизни? Если исключить многоженство, то можно сказать, что есть связь один к одному между мужем и женой. Хотя если даже сказать, что многоженство разрешено, то все равно у каждой жены может быть только один муж. Точно так же можно сказать про родителей. У каждого человека может быть только один биологический отец и только одна биологическая мать. Явная связь один-к-одному. Пока писал это, пришла в голову мысль: а зачем тогда разделять связь один-к-одному на две записи в разных таблицах, если у них и так связь однозначная? Сам и ответ придумал. Эти записи могут быть еще связаны с другими записями в других связях. О чем это я? Еще один пример из связей один-к-одному — это страна и президент. Можно же записать в таблице “страна” все данные о президенте? Да можно, SQL и слова не скажет. Вот только если подумать, что президент к тому же еще и человек. И еще у него может быть жена (еще одна связь один-к-одному) и дети (еще одна связь один-ко-многим) и тогда получается, что это уже нужно будет страну связывать с женой и детьми президента…. Звучит бредово, да? :D Примеров других может быть множество и для этой связи. Причем в такой ситуации можно добавлять внешний ключ в обе таблицы, в отличие от связи one-to-many.
Многие ко многим (many-to-many)
Если у нас есть две таблицы А и В.
А может относиться к В как один ко многим.
Но и В может относиться к А, как один ко многим.
А это значит, у них связь многие ко многим.
- NOT NULL означает, что поле всегда должно быть заполнено, и если мы этого не сделаем, то SQL скажет нам об этом;
- UNIQUE говорит о том, что поле или связка полей должны быть уникальна в таблице. Часто бывает так, что помимо уникального идентификатора уникальным для каждой записи должно быть еще одно поле. И UNIQUE отвечает как раз за это дело.
Соединения (Джоины)
В предыдущей части я готовил вас к тому, чтобы сразу было понятно, что такое джоины и где их использовать. Потому что я глубоко убежден, что как только придет понимание, сразу станет все очень просто, и все статьи о джоинах будут ясными, как очи младенца :D Грубо и в общем, джоины — это получение результата из нескольких таблиц путем СОЕДИНЕНИЯ (джоина из английского join). И все…) А чтобы соединить, нужно указать поле, по которому будут соединяться таблицы. Не так страшен черт, как его малюют, да?) Далее просто поговорим о том, какие бывают джоины и как их использовать. Типов джоинов много, и все мы рассматривать не будем. Только те, которые нам реально нужны. Потому такие экзотические джоины как Cross и Natural нам не интересны. Совсем забыл, нам нужно запомнить еще один нюанс: у таблиц и полей могут быть алиасы — псевдонимы. Они удобно используются для джоинов. Например, можно сделать так: SELECT * FROM table1; если в запросе часто будет использоваться table1, то можно ему дать псевдоним: SELECT* FROM table1 as t1; или еще проще написать: SELECT * FROM table1 t1; и тогда дальше в запросе можно будет использовать t1 как псевдоним для этой таблицы.
INNER JOIN

Самый распространенный и простой джоин. Он говорит о том, что когда у нас есть две таблицы и поле, по которому его можно соединить, будут выбраны все записи, связи которых существуют в двух таблицах. Сложно сказал как-то. Посмотрим на примере: Добавим в нашу БД cities по одной записи. Одну запись в города и одну — в страны: $ INSERT INTO country VALUES(5, "Uzbekistan", 34036800); и $ INSERT INTO city (name, population) VALUES("Tbilisi", 1171100); Мы добавили страну, у которой нет города в нашей таблице, и город, который не привязан к стране в нашей таблице. Так вот, INNER JOIN занимается тем, что выдает все записи на те соединения, которые есть в двух таблицах. Вот как выглядит общий синтаксис, когда мы хотим соединить две таблицы table1 и table2: SELECT * FROM table1 t1 INNER JOIN table2 ON t1.id = t2.t1_id; и тогда будут выданы все записи, которые имеют связь в двух таблицах. Для нашего случая, когда мы хотим получить вместе с городами еще и информацию для стран, получится так: $ SELECT * FROM city ci INNER JOIN country co ON ci.country_id = co.id; Здесь хоть имена и совпадают, но можно отчетливо увидеть, что идут вначале поля городов, потом поля стран. А тех двух записей, которые мы добавили выше, там нет. Потому что INNER JOIN именно так и работает.
LEFT JOIN

Бывают случаи, и довольно-таки часто, когда нас не устраивает потеря полей главной таблицы из-за того, что к ней нет записи в смежной таблице. Для этого дела и нужен LEFT JOIN. Если мы в нашем предыдущем запросе укажем вместо INNER — LEFT, у нас в ответе добавится еще один город — Tbilisi: $ SELECT * FROM city ci LEFT JOIN country co ON ci.country_id = co.id; Новая запись про Тбилиси есть и все, что относится к стране, там стоит в null . Зачастую это так и используется.
RIGHT JOIN

Здесь будет отличие от LEFT JOIN в том, что выбираться все поля будут не слева, а справа в соединении. То есть, будут взяты не города, а все страны: $ SELECT * FROM city ci RIGHT JOIN country co ON ci.country_id = co.id; Теперь видно, что в этом случае Тбилиси не будет, зато будет у нас Узбекистан. Вот как-то так…))
Закрепляем Джоины
- INNER JOIN — это только пересечение множеств, то есть те записи, у которых есть связи на две таблицы — А и В;
- LEFT JOIN — это все записи из таблицы A, включая все записи из таблицы В, которые имеют пересечение (связь) с А;
- RIGHT JOIN — это с точностью до наоборот к LEFT JOIN — все записи в таблице В и записи из А, которые имеют связь.
Домашнее задание
На этот раз задания будут ооочень интересные и все те, кто успешно их решит, может не сомневаться, что готов к началу работы со стороны SQL! Задания не разжеванные и написаны были для мидлов, так что легко и скучно не будет вам :) Я дам вам недельку на то, чтобы сделать задания самому, и потом выпущу отдельную статью с подробным разбором решения тех заданий, что я вам дал.
Собственно задание:
- Написать SQL script создания таблицы ‘Student’ с полями: id (primary key), name, last_name, e_mail (unique).
- Написать SQL script создания таблицы ‘Book’ с полями: id, title (id + title = primary key). Связать ‘Student’ и ‘Book’ связью ‘Student’ one-to-many ‘Book’.
- Написать SQL script создания таблицы ‘Teacher’ с полями: id (primary key), name, last_name, e_mail (unique), subject.
- Связать ‘Student’ и ‘Teacher’ связью ‘Student’ many-to-many Teacher’.
- Выбрать ‘Student’ у которых в фамилии есть ‘oro’, например ‘Sid oro v’, ‘V oro novsky’.
- Выбрать из таблицы ‘Student’ все фамилии (‘last_name’) и количество их повторений. Считать, что в базе есть однофамильцы. Отсортировать по количеству в порядке убывания. Выглядеть должно так:
last_name quantity Petrov 15 Ivanov 12 Sidorov 3 - Выбрать из ‘Student’ топ 3 самых повторяющихся имен ‘name’. Отсортировать по количеству в порядке убывания. Выглядеть должно так:
name quantity Alexander 27 Sergey 10 Peter 7 - Выбрать ‘Student’, у которых самое большое количество ‘Book’ и связанных с ним ‘Teacher’.Отсортировать по количеству в порядке убывания. Выглядеть должно так:
Teacher’s last_name Student’s last_name Book’s quantity Petrov Sidorov 7 Ivanov Smith 5 Petrov Kankava 2> - Выбрать ‘Teacher’, у которых самое большое количество ‘Book’ у всех его ‘Student’. Отсортировать по количеству в порядке убывания. Выглядеть должно так:
Teacher’s last_name Book’s quantity Petrov 9 Ivanov 5 - Выбрать ‘Teacher’ у которых количество ‘Book’ у всех его ‘Student’ находится между 7-ю и 11-и. Отсортировать по количеству в порядке убывания. Выглядеть должно так:
Teacher’s last_name Book’s quantity Petrov 11 Sidorov 9 Ivanov 7 - Вывести всех ‘last_name’ и ‘name’ всех ‘Teacher’ и ‘Student’ с полем ‘type‘ (student или teacher). Отсортировать в алфавитном порядке по ‘last_name’. Выглядеть должно так:
last_name type Ivanov student Kankava teacher Smith student Sidorov teacher Petrov teacher - Добавить к существующей таблице ‘Student’ колонку ‘rate’, в которой будет храниться курс, на котором студент сейчас находится (числовое значение от 1 до 6).
- Этот пункт не обязателен к выполнению, но будет плюсом. Написать функцию, которая пройдется по всем ‘Book’, и выведет через запятую все ‘title’.
Вывод
Несколько затянулась серия про БД. Согласен. Тем не менее, мы проделали большой путь и в результате выходим со знанием дела! Всем спасибо за прочтение, напоминаю, что все кто хочет идти дальше и следить за проектом, нужно создать аккаунт на GitHub и подписаться на мой аккаунт :) Дальше больше — поговорим о мавене и докере. Всем спасибо за прочтение. Повторю еще раз: дорогу осилит идущий ;)
Читайте также: